> ## Documentation Index
> Fetch the complete documentation index at: https://koreai.mintlify.site/llms.txt
> Use this file to discover all available pages before exploring further.
# Adding Custom Prompts
[Back to Prompts Library](/ai-for-service/generative-ai-tools/prompts-library)
Reference and procedures for managing Custom prompts in the Prompts Library.
***
## Add a Custom Prompt
### Prerequisites
Integrate a pre-built or custom LLM before creating a prompt. See [LLM Integration](/ai-for-service/generative-ai-tools/llm-integration).
### Steps
1. Go to **Generative AI Tools** > **Prompts Library**.
2. Click **+ New Prompt** (top right).
3. Enter the **Prompt Name**, then select the **Feature** and **Model**.
.png?fit=max&auto=format&n=s3bkaKmzowgJ31et&q=85&s=7518d082701b1fee16b8addbe380e8ba) 4. The **Configuration** section (endpoint URL, auth, headers) is auto-populated from the model integration and is read-only.
4. The **Configuration** section (endpoint URL, auth, headers) is auto-populated from the model integration and is read-only.
.png?fit=max&auto=format&n=s3bkaKmzowgJ31et&q=85&s=6a6aa787806659f6131c193c9f38a2b1) 5. In the **Request** section, create a prompt or import an existing one.
5. In the **Request** section, create a prompt or import an existing one.
.png?fit=max&auto=format&n=s3bkaKmzowgJ31et&q=85&s=6500f64bfe15c61130bcab6f2a0a6a1e) **To import an existing prompt:**
1. Click **Import from Prompts and Requests Library**.
**To import an existing prompt:**
1. Click **Import from Prompts and Requests Library**.
 2. Select the **Feature**, **Model**, and **Prompt**. Hover and click **Preview Prompt** to review before importing.
You can interchange prompts between features.
3. Click **Confirm** to import the prompt into the JSON body.
**To create from scratch:**
Click **Start from scratch** and enter the JSON request for the LLM.
2. Select the **Feature**, **Model**, and **Prompt**. Hover and click **Preview Prompt** to review before importing.
You can interchange prompts between features.
3. Click **Confirm** to import the prompt into the JSON body.
**To create from scratch:**
Click **Start from scratch** and enter the JSON request for the LLM.
.png?fit=max&auto=format&n=s3bkaKmzowgJ31et&q=85&s=c4d2e13be4d591f3f56878c9f2ae51b6) 6. (Optional) Toggle **Stream Response** to enable streaming. Responses are sent incrementally in real time instead of waiting for the full response.
6. (Optional) Toggle **Stream Response** to enable streaming. Responses are sent incrementally in real time instead of waiting for the full response.
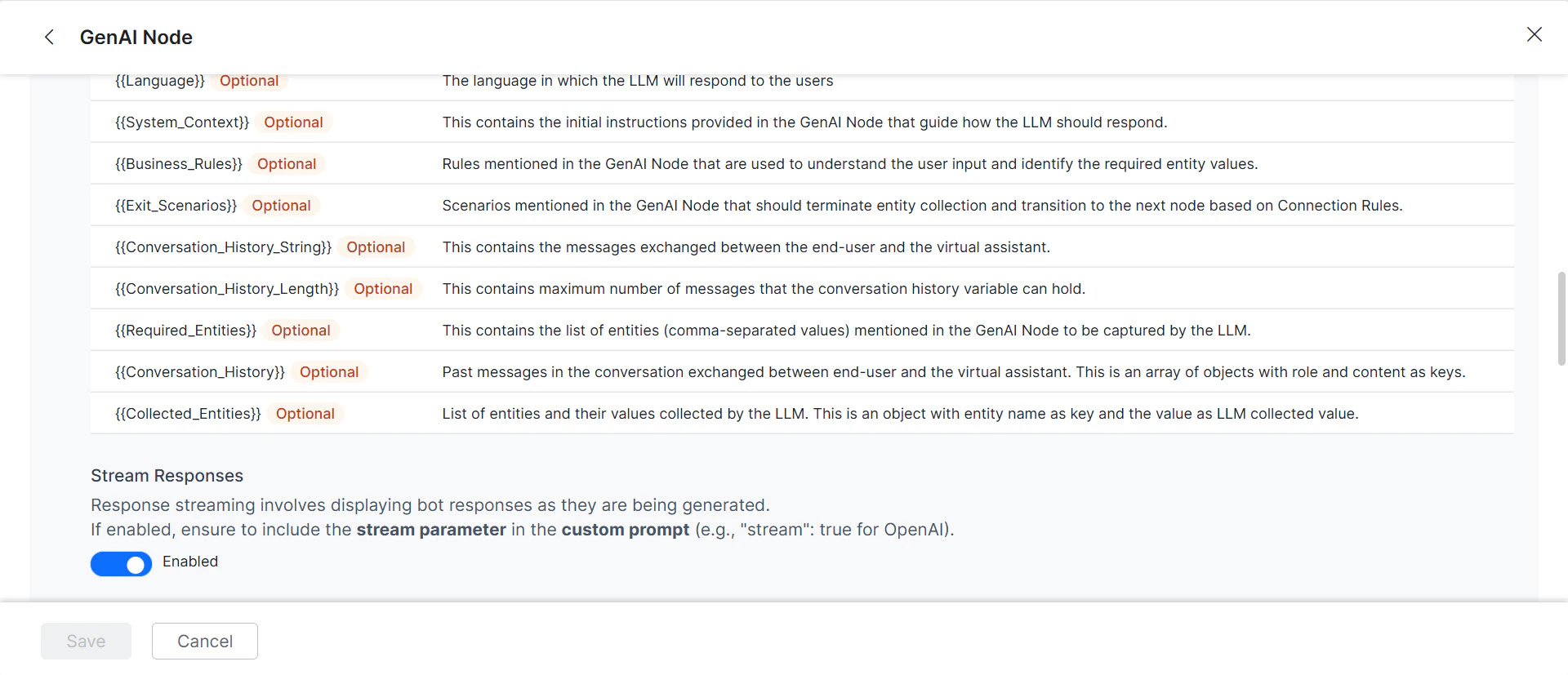 * Add `"stream": true` to the custom prompt when streaming is enabled. The saved prompt displays a "streaming" tag.
* Enabling streaming disables the "Exit Scenario" field.
Streaming applies only to Agent Node and Prompt Node features using OpenAI and Azure OpenAI models.
7. Fill in the **Sample Context Values** and click **Test**. If successful, the LLM response is displayed; otherwise an error appears. See [Dynamic Variables](/ai-for-service/automation/agent-node#reference-dynamic-variables)
* Add `"stream": true` to the custom prompt when streaming is enabled. The saved prompt displays a "streaming" tag.
* Enabling streaming disables the "Exit Scenario" field.
Streaming applies only to Agent Node and Prompt Node features using OpenAI and Azure OpenAI models.
7. Fill in the **Sample Context Values** and click **Test**. If successful, the LLM response is displayed; otherwise an error appears. See [Dynamic Variables](/ai-for-service/automation/agent-node#reference-dynamic-variables)
.png?fit=max&auto=format&n=s3bkaKmzowgJ31et&q=85&s=c2a180d09d959aa535bc9d90feb5d0c5) 8. **Map the response key:** In the JSON response, double-click the key that holds the relevant information (for example, `content`). The Platform generates a **Response Path** for that location. Click **Save**.
8. **Map the response key:** In the JSON response, double-click the key that holds the relevant information (for example, `content`). The Platform generates a **Response Path** for that location. Click **Save**.
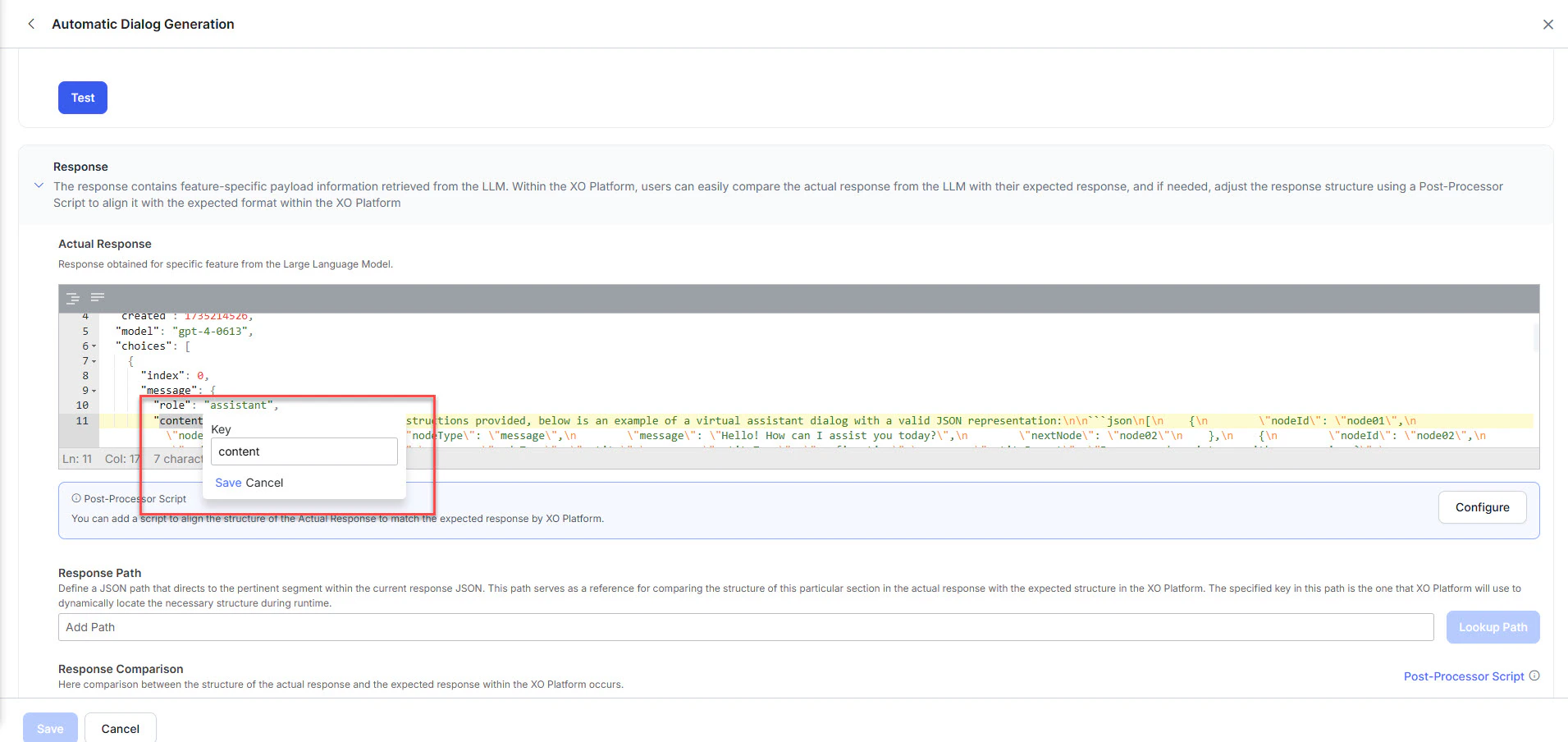 9. Click **Lookup Path** to validate the path.
9. Click **Lookup Path** to validate the path.
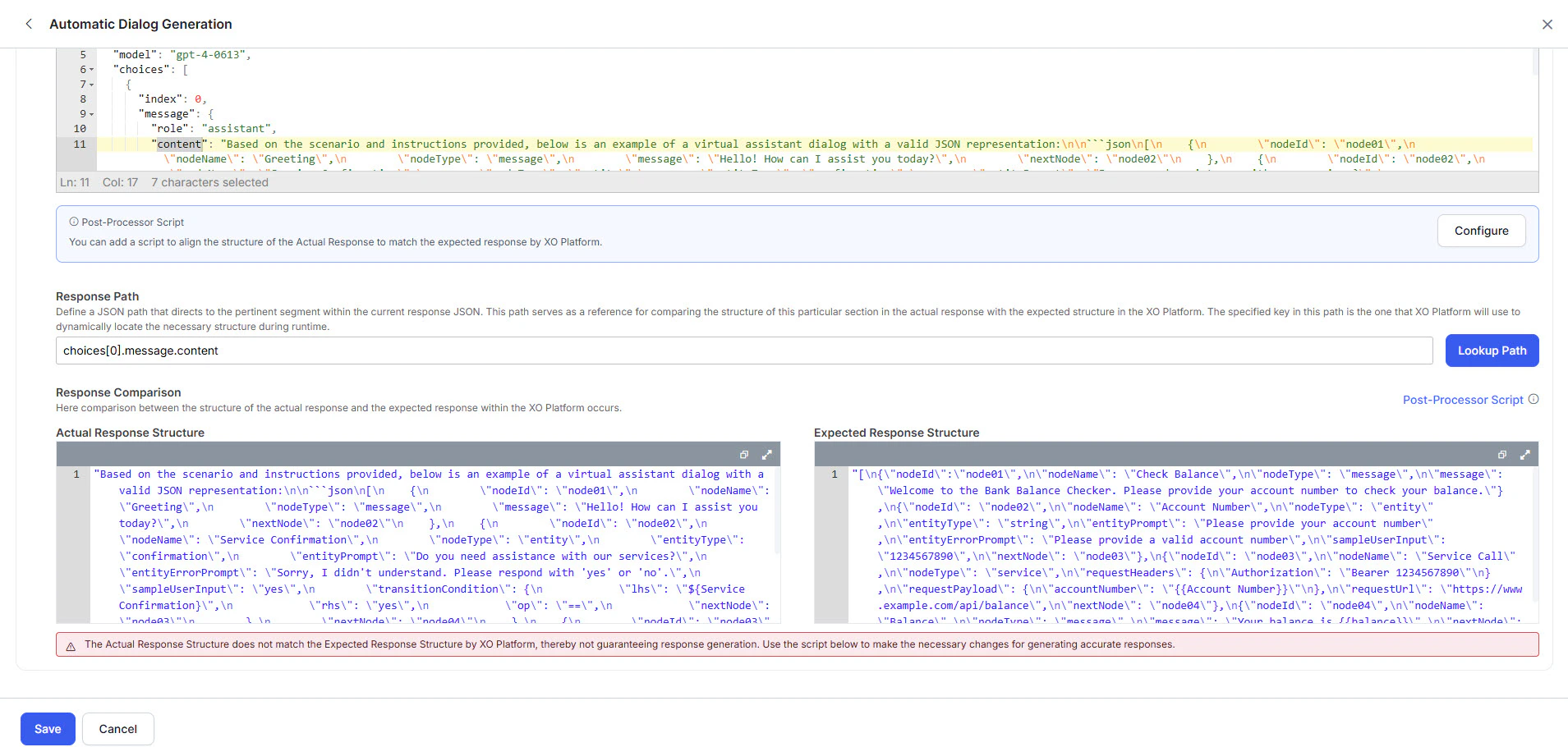 10. Review the **Actual Response** and **Expected Response**:
* **Green (match):** Click **Save**. Skip to step 12.
10. Review the **Actual Response** and **Expected Response**:
* **Green (match):** Click **Save**. Skip to step 12.
.png?fit=max&auto=format&n=s3bkaKmzowgJ31et&q=85&s=f5dcbe2fef35a83b0e84f9304f1227a6) * **Red (mismatch):** Click **Configure** to open the Post Processor Script editor.
* **Red (mismatch):** Click **Configure** to open the Post Processor Script editor.
.png?fit=max&auto=format&n=s3bkaKmzowgJ31et&q=85&s=51bb008b090cf8f7c9cfbdc6da7e7dfd) 1. Enter the **Post Processor Script** and click **Save & Test**.
1. Enter the **Post Processor Script** and click **Save & Test**.
.png?fit=max&auto=format&n=s3bkaKmzowgJ31et&q=85&s=1e201d5203096337ef4d1d2378cae35b) 2. Verify the result, then click **Save**. The responses turn green.
2. Verify the result, then click **Save**. The responses turn green.
.png?fit=max&auto=format&n=s3bkaKmzowgJ31et&q=85&s=82831155d912247ddb93866b40fd4fe1) 11. (Optional) If **Token Usage Limits** are enabled for your custom model, map the token keys for accurate tracking:
* **Request Tokens key:** `usage.input_tokens`
* **Response Tokens key:** `usage.output_tokens`
11. (Optional) If **Token Usage Limits** are enabled for your custom model, map the token keys for accurate tracking:
* **Request Tokens key:** `usage.input_tokens`
* **Response Tokens key:** `usage.output_tokens`
 Without this mapping, the Platform can't calculate token consumption, which may lead to untracked usage and unexpected costs.
12. Click **Save**. The prompt appears in the Prompts Library.
Without this mapping, the Platform can't calculate token consumption, which may lead to untracked usage and unexpected costs.
12. Click **Save**. The prompt appears in the Prompts Library.