> ## Documentation Index
> Fetch the complete documentation index at: https://koreai.mintlify.site/llms.txt
> Use this file to discover all available pages before exploring further.
# XO GPT Answer Generation Model
[Back to XO GPT Model Specifications](/ai-for-service/generative-ai-tools/xo-gpt-module#xo-gpt-model-specifications)
The XO GPT Answer Generation model uses Retrieval-Augmented Generation (RAG) to generate accurate, contextually relevant answers from domain-specific data. It's a fine-tuned LLM that addresses key limitations of using commercial models out-of-the-box.
***
## Challenges with Commercial Models
| Challenge | Impact |
| -------------------------- | ----------------------------------------------------------------------------------------------- |
| **Latency** | High processing times affect user experience in real-time or high-volume scenarios. |
| **Cost** | Per-request pricing scales poorly for large deployments. |
| **Data Governance** | Sending queries to external models raises privacy and security concerns. |
| **Lack of Customization** | General-purpose models aren't tuned for specific industries or use cases. |
| **Limited Control** | Minimal ability to correct or refine model behavior for incorrect outputs. |
| **Compliance Constraints** | Some industries have regulatory requirements that commercial LLM providers don't fully support. |
***
## How It Works
The XO GPT Answer Generation model activates immediately after the retrieval phase in the RAG pipeline. It takes retrieved data chunks and generates accurate, contextually relevant answers.
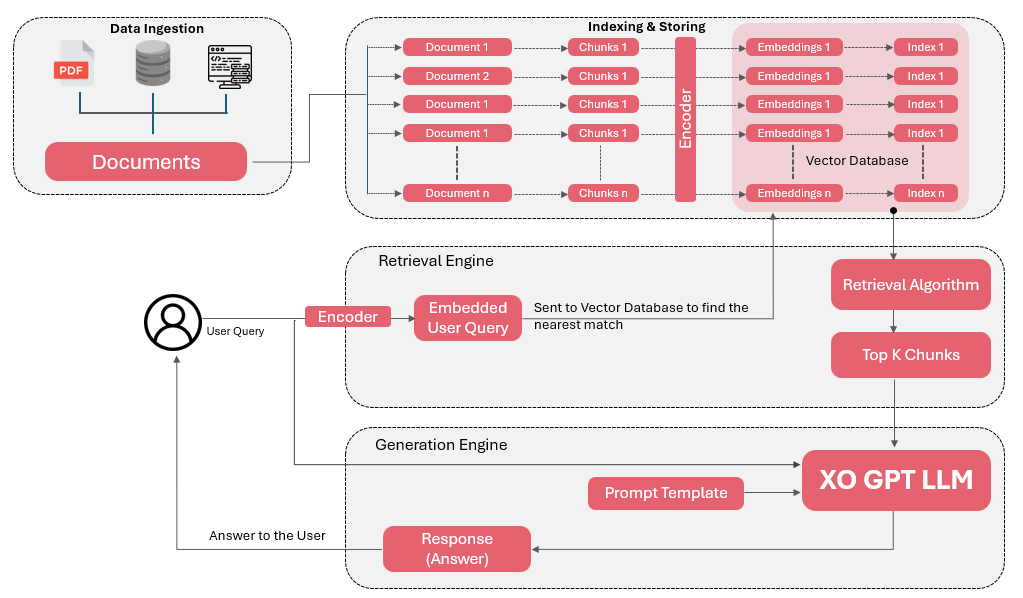 **Key assumptions:**
* Answers are generated from text-based data chunks only (not images or video).
* Input queries have been rephrased by the XO GPT User Query Rephrasing Model.
* Retrieved data chunks are assumed to be accurate and relevant.
* Responses are based solely on text; content within links or embedded images isn't included.
***
## Benefits
**Key assumptions:**
* Answers are generated from text-based data chunks only (not images or video).
* Input queries have been rephrased by the XO GPT User Query Rephrasing Model.
* Retrieved data chunks are assumed to be accurate and relevant.
* Responses are based solely on text; content within links or embedded images isn't included.
***
## Benefits
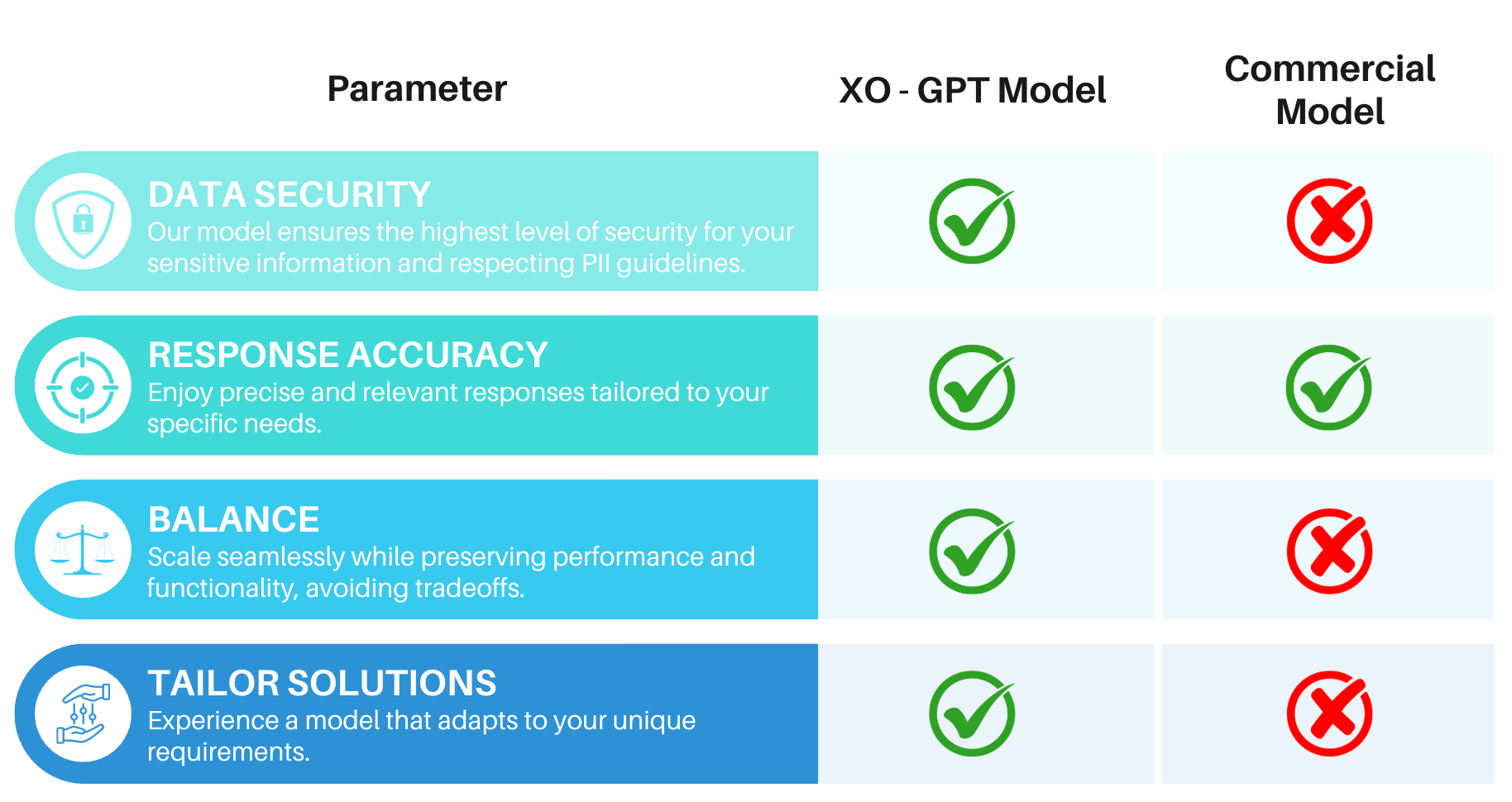 ### Consistent and Accurate
RAG-based retrieval delivers contextually relevant and precise answers. See [Model Benchmarks](#model-benchmarks) for latency and accuracy metrics.
### Cost-Effective
For Enterprise Tier customers, XO GPT eliminates commercial model usage costs. Example comparison (10 input tokens/question, 10,000 daily Q\&A pairs, 80 tokens/answer):
| Model | Input \$/MTok | Output \$/MTok | Input \$/Year | Output \$/Year | Total \$/Year |
| ----------- | ------------- | -------------- | ------------- | -------------- | ------------- |
| GPT-4 Turbo | \$30 | \$60 | \$1,095 | \$17,520 | \$18,615 |
| GPT-4 | \$10 | \$30 | \$365 | \$8,760 | \$9,125 |
| GPT-4o Mini | \$0.15 | \$0.60 | \$5.48 | \$175.20 | \$180.68 |
### Enhanced Security
No client or user data is used for model retraining.
**Guardrails:** Content moderation, behavioral guidelines, response oversight, input validation, and usage controls.
**AI Safety:** Ethical guidelines, bias monitoring, transparency, and continuous improvement.
Performance, features, and language support may vary by implementation. Test thoroughly in your environment before production use.
***
## Use Cases
| Domain | Use Cases |
| ---------------- | ------------------------------------------------------------------------------------------------------------------------------------ |
| Healthcare | Answering patient queries from medical records; assisting with evidence-based diagnosis; providing drug information and interactions |
| Finance | Answering loan eligibility questions; providing personalized financial advice; assisting with tax queries |
| E-commerce | Recommending products; answering shipping/returns/order status questions; providing product comparisons |
| Education | Assisting with homework; explaining complex concepts; recommending study materials |
| Legal | Answering legal queries from case law; assisting with contract review; providing info on legal rights |
| Customer Support | Automating FAQ responses; troubleshooting common issues; providing personalized support |
| Human Resources | Answering policy and benefits questions; assisting with recruitment; guiding performance evaluations |
***
## Sample Output
**Ingested chunks:**
* **chk-1:** A home loan is a secured loan obtained to purchase property by offering it as collateral. Calculation involves loan amount, interest rate, tenure, and borrower profile.
* **chk-4:** EMI = \[P × R × (1+R)^N] / \[(1+R)^N−1], where P = principal, R = monthly interest rate, N = number of installments.
**Q: How do you compute EMI?**
> The EMI is calculated using the formula: EMI = \[P × R × (1+R)^N] / \[(1+R)^N−1], where P is the principal loan amount, R is the monthly interest rate, and N is the number of monthly installments \[chk-4].
**Q: What's a home loan? What's photosynthesis?**
> I found only the answer to one question 'what's a home loan?': A home loan is a secured loan obtained to purchase property by offering it as collateral \[chk-1]. The remaining questions can't be answered from the given context.
***
## Model Building Process
See [Model Building Process](/ai-for-service/generative-ai-tools/xogpt-model-specifications#model-building-process).
***
## Model Benchmarks
| Version | Accuracy | TPS | Latency (s) | Benchmark | Test Data |
| ------- | -------- | --- | ----------- | ------------------------------------ | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| v3.0 | 97% | 37 | 0.92 | [Summary v3](#benchmarks-summary-v3) | [Results v3](https://raw.githubusercontent.com/Koredotcom/docs-v2/refs/heads/main/ai-for-service/generative-ai-tools/test-date-and-results/xogpt-answer-generation-v3.0.xlsx) |
| v2.0 | 96% | 54 | 1.03 | [Summary v2](#benchmarks-summary-v2) | [Results v2](https://raw.githubusercontent.com/Koredotcom/docs-v2/refs/heads/main/ai-for-service/generative-ai-tools/test-date-and-results/xogpt-answer-generation-v2.0.xlsx) |
| v1.0 | 94% | 20 | 1.36 | [Summary v1](#benchmarks-summary-v1) | [Results v1](https://raw.githubusercontent.com/Koredotcom/docs-v2/refs/heads/main/ai-for-service/generative-ai-tools/test-date-and-results/xogpt-answer-generation-v1.0.xlsx) |
***
## Version 3.0
### Model Choice
Base model: [Llama 3.1 8B Instruct](https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct)
| Base Model | Developer | Language | Release Date | Status | Knowledge Cutoff |
| --------------------- | --------- | ------------- | ------------ | ------ | ---------------- |
| Llama 3.1 8B Instruct | Meta | Multi-lingual | July 2024 | Static | December 2023 |
### Prompt Tuning
Prompts are designed to produce clear, well-structured outputs with a consistent tone. Each prompt variation is evaluated across multiple categories (toxicity, bias, ambiguity, hallucination, logical consistency, robustness) in English and multiple translated languages. The prompt with the highest accuracy and reliability across all scenarios is selected.
### AWQ Model Quantization
AWQ (Activation-aware Weight Quantization) reduces memory and compute requirements while maintaining accuracy.
| Parameter | Description | Value |
| ----------------------- | --------------------------------------------------- | ----------------------------- |
| Zero Point | Include zero-point for better weight representation | True |
| Quantization Group Size | Weight group size for quantization | 128 |
| Weight Precision | Bits used to represent weights | 4 |
| Quantization Version | AWQ version optimized for GEMM | "GEMM" |
| Computation Data Type | Data type for inference | torch.float16 |
| Model Loading | Reduced CPU memory usage | `{"low_cpu_mem_usage": True}` |
| Tokenizer Loading | Remote code compatibility | `trust_remote_code=True` |
### Model Usage Notes
* **Context-only responses:** The model responds based solely on the source document. It doesn't use external knowledge.
* **Language consistency:** Query and source document must be in the same language.
* **Output formatting:** Supports formatting cues in the query (for example, "provide the answer in bullet points", "explain step-by-step").
### Benchmarks Summary v3
Comparison models: Llama 3.1 8B, Claude 3.5 Sonnet, Mistral 7B v2.
### Consistent and Accurate
RAG-based retrieval delivers contextually relevant and precise answers. See [Model Benchmarks](#model-benchmarks) for latency and accuracy metrics.
### Cost-Effective
For Enterprise Tier customers, XO GPT eliminates commercial model usage costs. Example comparison (10 input tokens/question, 10,000 daily Q\&A pairs, 80 tokens/answer):
| Model | Input \$/MTok | Output \$/MTok | Input \$/Year | Output \$/Year | Total \$/Year |
| ----------- | ------------- | -------------- | ------------- | -------------- | ------------- |
| GPT-4 Turbo | \$30 | \$60 | \$1,095 | \$17,520 | \$18,615 |
| GPT-4 | \$10 | \$30 | \$365 | \$8,760 | \$9,125 |
| GPT-4o Mini | \$0.15 | \$0.60 | \$5.48 | \$175.20 | \$180.68 |
### Enhanced Security
No client or user data is used for model retraining.
**Guardrails:** Content moderation, behavioral guidelines, response oversight, input validation, and usage controls.
**AI Safety:** Ethical guidelines, bias monitoring, transparency, and continuous improvement.
Performance, features, and language support may vary by implementation. Test thoroughly in your environment before production use.
***
## Use Cases
| Domain | Use Cases |
| ---------------- | ------------------------------------------------------------------------------------------------------------------------------------ |
| Healthcare | Answering patient queries from medical records; assisting with evidence-based diagnosis; providing drug information and interactions |
| Finance | Answering loan eligibility questions; providing personalized financial advice; assisting with tax queries |
| E-commerce | Recommending products; answering shipping/returns/order status questions; providing product comparisons |
| Education | Assisting with homework; explaining complex concepts; recommending study materials |
| Legal | Answering legal queries from case law; assisting with contract review; providing info on legal rights |
| Customer Support | Automating FAQ responses; troubleshooting common issues; providing personalized support |
| Human Resources | Answering policy and benefits questions; assisting with recruitment; guiding performance evaluations |
***
## Sample Output
**Ingested chunks:**
* **chk-1:** A home loan is a secured loan obtained to purchase property by offering it as collateral. Calculation involves loan amount, interest rate, tenure, and borrower profile.
* **chk-4:** EMI = \[P × R × (1+R)^N] / \[(1+R)^N−1], where P = principal, R = monthly interest rate, N = number of installments.
**Q: How do you compute EMI?**
> The EMI is calculated using the formula: EMI = \[P × R × (1+R)^N] / \[(1+R)^N−1], where P is the principal loan amount, R is the monthly interest rate, and N is the number of monthly installments \[chk-4].
**Q: What's a home loan? What's photosynthesis?**
> I found only the answer to one question 'what's a home loan?': A home loan is a secured loan obtained to purchase property by offering it as collateral \[chk-1]. The remaining questions can't be answered from the given context.
***
## Model Building Process
See [Model Building Process](/ai-for-service/generative-ai-tools/xogpt-model-specifications#model-building-process).
***
## Model Benchmarks
| Version | Accuracy | TPS | Latency (s) | Benchmark | Test Data |
| ------- | -------- | --- | ----------- | ------------------------------------ | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| v3.0 | 97% | 37 | 0.92 | [Summary v3](#benchmarks-summary-v3) | [Results v3](https://raw.githubusercontent.com/Koredotcom/docs-v2/refs/heads/main/ai-for-service/generative-ai-tools/test-date-and-results/xogpt-answer-generation-v3.0.xlsx) |
| v2.0 | 96% | 54 | 1.03 | [Summary v2](#benchmarks-summary-v2) | [Results v2](https://raw.githubusercontent.com/Koredotcom/docs-v2/refs/heads/main/ai-for-service/generative-ai-tools/test-date-and-results/xogpt-answer-generation-v2.0.xlsx) |
| v1.0 | 94% | 20 | 1.36 | [Summary v1](#benchmarks-summary-v1) | [Results v1](https://raw.githubusercontent.com/Koredotcom/docs-v2/refs/heads/main/ai-for-service/generative-ai-tools/test-date-and-results/xogpt-answer-generation-v1.0.xlsx) |
***
## Version 3.0
### Model Choice
Base model: [Llama 3.1 8B Instruct](https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct)
| Base Model | Developer | Language | Release Date | Status | Knowledge Cutoff |
| --------------------- | --------- | ------------- | ------------ | ------ | ---------------- |
| Llama 3.1 8B Instruct | Meta | Multi-lingual | July 2024 | Static | December 2023 |
### Prompt Tuning
Prompts are designed to produce clear, well-structured outputs with a consistent tone. Each prompt variation is evaluated across multiple categories (toxicity, bias, ambiguity, hallucination, logical consistency, robustness) in English and multiple translated languages. The prompt with the highest accuracy and reliability across all scenarios is selected.
### AWQ Model Quantization
AWQ (Activation-aware Weight Quantization) reduces memory and compute requirements while maintaining accuracy.
| Parameter | Description | Value |
| ----------------------- | --------------------------------------------------- | ----------------------------- |
| Zero Point | Include zero-point for better weight representation | True |
| Quantization Group Size | Weight group size for quantization | 128 |
| Weight Precision | Bits used to represent weights | 4 |
| Quantization Version | AWQ version optimized for GEMM | "GEMM" |
| Computation Data Type | Data type for inference | torch.float16 |
| Model Loading | Reduced CPU memory usage | `{"low_cpu_mem_usage": True}` |
| Tokenizer Loading | Remote code compatibility | `trust_remote_code=True` |
### Model Usage Notes
* **Context-only responses:** The model responds based solely on the source document. It doesn't use external knowledge.
* **Language consistency:** Query and source document must be in the same language.
* **Output formatting:** Supports formatting cues in the query (for example, "provide the answer in bullet points", "explain step-by-step").
### Benchmarks Summary v3
Comparison models: Llama 3.1 8B, Claude 3.5 Sonnet, Mistral 7B v2.
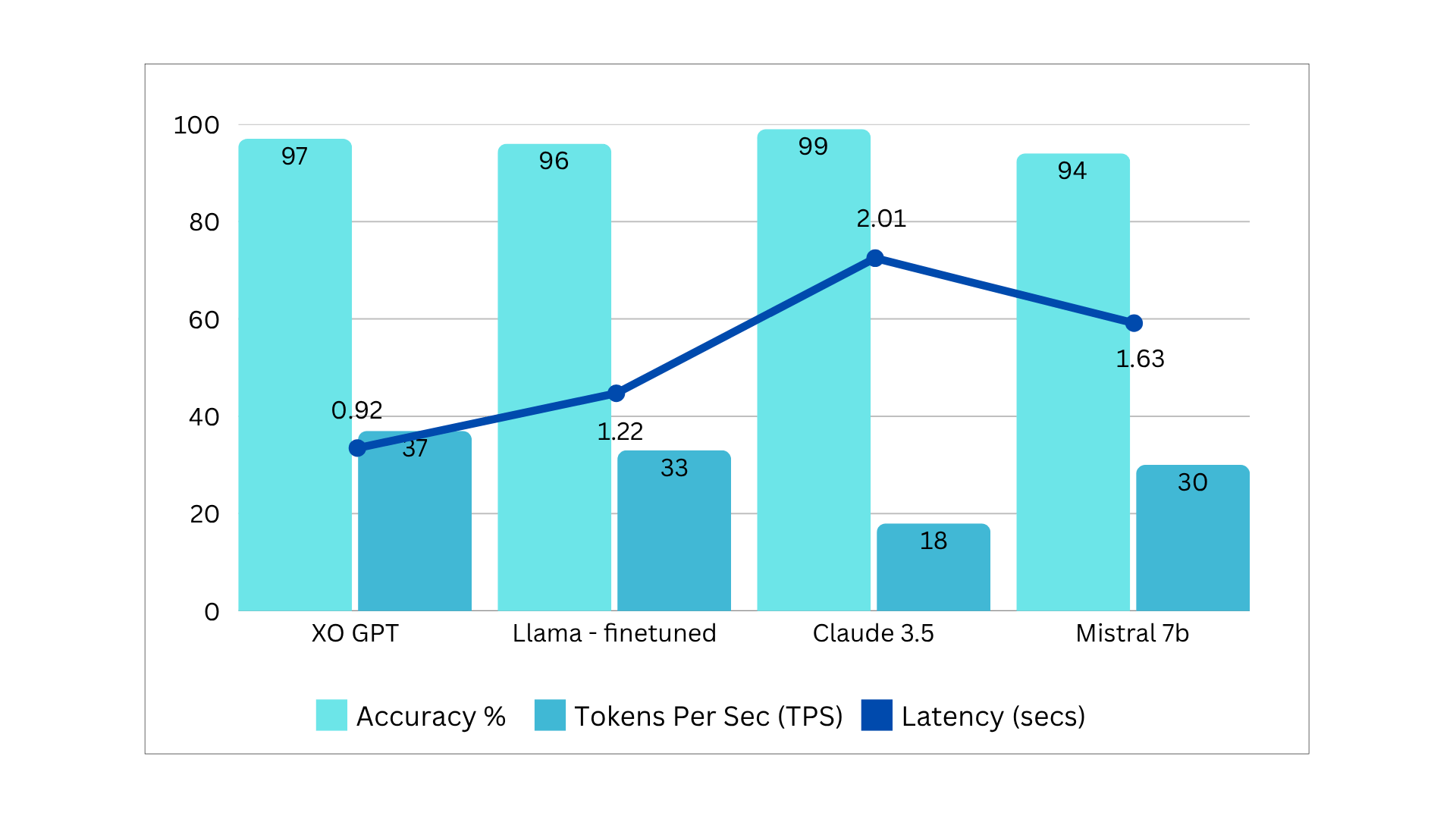 See [Test Data and Results v3](https://raw.githubusercontent.com/Koredotcom/docs-v2/refs/heads/main/ai-for-service/generative-ai-tools/test-date-and-results/xogpt-answer-generation-v3.0.xlsx) for full details.
***
## Version 2.0
### Model Choice
Base model: [Llama 3.1 8B Instruct](https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct)
| Base Model | Developer | Language | Release Date | Status | Knowledge Cutoff |
| --------------------- | --------- | ------------- | ------------ | ------ | ---------------- |
| Llama 3.1 8B Instruct | Meta | Multi-lingual | July 2024 | Static | December 2023 |
### Fine-Tuning Parameters
| Parameter | Description | Value |
| ----------------------- | ----------------------------------------- | ------------------------------------------ |
| Load in 4-bit Precision | Reduce memory by loading weights at 4-bit | True |
| Use Double Quantization | Improve accuracy with double quantization | True |
| 4-bit Quantization Type | Type of 4-bit quantization | nf4 |
| Computation Data Type | Data type for 4-bit quantized weights | torch.float16 |
| LoRA Rank | Rank of low-rank decomposition | 32 |
| LoRA Alpha | LoRA scaling factor | 16 |
| LoRA Dropout Rate | Dropout to prevent overfitting | 0.05 |
| Bias Term Inclusion | Add bias terms in LoRA layers | — |
| Task Type | LoRA task type | CAUSAL\_LM |
| Targeted Modules | Model layers where LoRA is applied | `['k_proj', 'q_proj', 'v_proj', 'o_proj']` |
### General Parameters
Infrastructure: 2× A10 GPUs. Requires an Agent AI License.
| Parameter | Description | Value |
| ------------------- | -------------------------- | ------------------ |
| Learning Rate | Rate toward loss minimum | 2e-4 (0.0002) |
| Batch Size | Examples per training step | 2 |
| Epochs | Passes over training data | 4 |
| Max Sequence Length | Maximum input length | 32768 |
| Optimizer | Optimization algorithm | paged\_adamw\_8bit |
### AWQ Model Quantization
Same configuration as v3.0. See [AWQ parameters above](#awq-model-quantization).
### Benchmarks Summary v2
Comparison models: Mistral 7B v2, Llama 3.1 8B, GPT-4o Mini, Claude 3.5 Sonnet.
See [Test Data and Results v3](https://raw.githubusercontent.com/Koredotcom/docs-v2/refs/heads/main/ai-for-service/generative-ai-tools/test-date-and-results/xogpt-answer-generation-v3.0.xlsx) for full details.
***
## Version 2.0
### Model Choice
Base model: [Llama 3.1 8B Instruct](https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct)
| Base Model | Developer | Language | Release Date | Status | Knowledge Cutoff |
| --------------------- | --------- | ------------- | ------------ | ------ | ---------------- |
| Llama 3.1 8B Instruct | Meta | Multi-lingual | July 2024 | Static | December 2023 |
### Fine-Tuning Parameters
| Parameter | Description | Value |
| ----------------------- | ----------------------------------------- | ------------------------------------------ |
| Load in 4-bit Precision | Reduce memory by loading weights at 4-bit | True |
| Use Double Quantization | Improve accuracy with double quantization | True |
| 4-bit Quantization Type | Type of 4-bit quantization | nf4 |
| Computation Data Type | Data type for 4-bit quantized weights | torch.float16 |
| LoRA Rank | Rank of low-rank decomposition | 32 |
| LoRA Alpha | LoRA scaling factor | 16 |
| LoRA Dropout Rate | Dropout to prevent overfitting | 0.05 |
| Bias Term Inclusion | Add bias terms in LoRA layers | — |
| Task Type | LoRA task type | CAUSAL\_LM |
| Targeted Modules | Model layers where LoRA is applied | `['k_proj', 'q_proj', 'v_proj', 'o_proj']` |
### General Parameters
Infrastructure: 2× A10 GPUs. Requires an Agent AI License.
| Parameter | Description | Value |
| ------------------- | -------------------------- | ------------------ |
| Learning Rate | Rate toward loss minimum | 2e-4 (0.0002) |
| Batch Size | Examples per training step | 2 |
| Epochs | Passes over training data | 4 |
| Max Sequence Length | Maximum input length | 32768 |
| Optimizer | Optimization algorithm | paged\_adamw\_8bit |
### AWQ Model Quantization
Same configuration as v3.0. See [AWQ parameters above](#awq-model-quantization).
### Benchmarks Summary v2
Comparison models: Mistral 7B v2, Llama 3.1 8B, GPT-4o Mini, Claude 3.5 Sonnet.
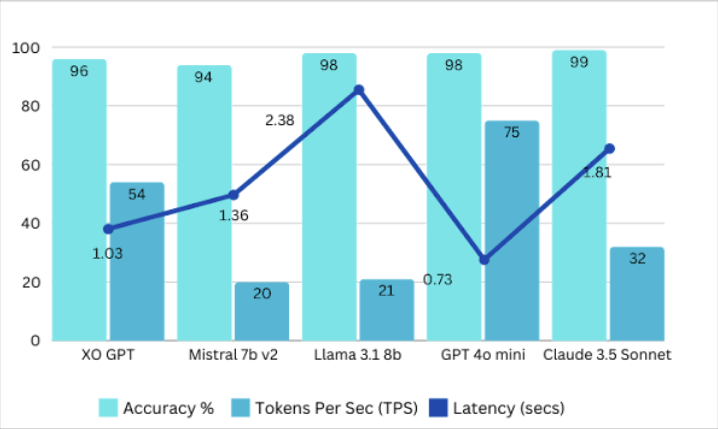 See [Test Data and Results v2](https://raw.githubusercontent.com/Koredotcom/docs-v2/refs/heads/main/ai-for-service/generative-ai-tools/test-date-and-results/xogpt-answer-generation-v2.0.xlsx) for full details.
***
## Version 1.0
### Model Choice
Base model: [Mistral 7B Instruct v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2)
| Base Model | Developer | Language | Release Date | Status | Knowledge Cutoff |
| ------------------------ | ---------- | ------------- | -------------- | ------ | ---------------- |
| Mistral 7B Instruct v0.2 | Mistral AI | Multi-lingual | September 2024 | Static | September 2024 |
### Fine-Tuning Parameters
| Parameter | Description | Value |
| ----------------------- | ----------------------------------------- | ------------------------------------------ |
| Load in 4-bit Precision | Reduce memory by loading weights at 4-bit | True |
| Use Double Quantization | Improve accuracy with double quantization | True |
| 4-bit Quantization Type | Type of 4-bit quantization | nf4 |
| Computation Data Type | Data type for 4-bit quantized weights | torch.float16 |
| LoRA Rank | Rank of low-rank decomposition | 32 |
| LoRA Alpha | LoRA scaling factor | 16 |
| LoRA Dropout Rate | Dropout to prevent overfitting | 0.05 |
| Bias Term Inclusion | Add bias terms in LoRA layers | — |
| Task Type | LoRA task type | CAUSAL\_LM |
| Targeted Modules | Model layers where LoRA is applied | `['k_proj', 'q_proj', 'v_proj', 'o_proj']` |
### General Parameters
Infrastructure: 2× A10 GPUs. Requires an Agent AI License.
| Parameter | Description | Value |
| ------------------- | -------------------------- | ------------------ |
| Learning Rate | Rate toward loss minimum | 1e-3 (0.001) |
| Batch Size | Examples per training step | 1 |
| Epochs | Passes over training data | 3 |
| Max Sequence Length | Maximum input length | 32768 |
| Optimizer | Optimization algorithm | paged\_adamw\_8bit |
### Benchmarks Summary v1
Comparison models: Llama 3.1 8B, GPT-4o Mini, Claude 3.5 Sonnet.
See [Test Data and Results v2](https://raw.githubusercontent.com/Koredotcom/docs-v2/refs/heads/main/ai-for-service/generative-ai-tools/test-date-and-results/xogpt-answer-generation-v2.0.xlsx) for full details.
***
## Version 1.0
### Model Choice
Base model: [Mistral 7B Instruct v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2)
| Base Model | Developer | Language | Release Date | Status | Knowledge Cutoff |
| ------------------------ | ---------- | ------------- | -------------- | ------ | ---------------- |
| Mistral 7B Instruct v0.2 | Mistral AI | Multi-lingual | September 2024 | Static | September 2024 |
### Fine-Tuning Parameters
| Parameter | Description | Value |
| ----------------------- | ----------------------------------------- | ------------------------------------------ |
| Load in 4-bit Precision | Reduce memory by loading weights at 4-bit | True |
| Use Double Quantization | Improve accuracy with double quantization | True |
| 4-bit Quantization Type | Type of 4-bit quantization | nf4 |
| Computation Data Type | Data type for 4-bit quantized weights | torch.float16 |
| LoRA Rank | Rank of low-rank decomposition | 32 |
| LoRA Alpha | LoRA scaling factor | 16 |
| LoRA Dropout Rate | Dropout to prevent overfitting | 0.05 |
| Bias Term Inclusion | Add bias terms in LoRA layers | — |
| Task Type | LoRA task type | CAUSAL\_LM |
| Targeted Modules | Model layers where LoRA is applied | `['k_proj', 'q_proj', 'v_proj', 'o_proj']` |
### General Parameters
Infrastructure: 2× A10 GPUs. Requires an Agent AI License.
| Parameter | Description | Value |
| ------------------- | -------------------------- | ------------------ |
| Learning Rate | Rate toward loss minimum | 1e-3 (0.001) |
| Batch Size | Examples per training step | 1 |
| Epochs | Passes over training data | 3 |
| Max Sequence Length | Maximum input length | 32768 |
| Optimizer | Optimization algorithm | paged\_adamw\_8bit |
### Benchmarks Summary v1
Comparison models: Llama 3.1 8B, GPT-4o Mini, Claude 3.5 Sonnet.
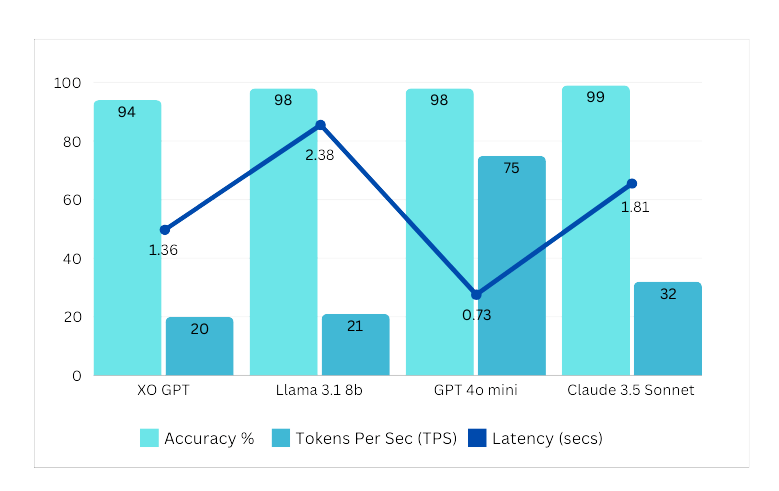 See [Test Data and Results v1](https://raw.githubusercontent.com/Koredotcom/docs-v2/refs/heads/main/ai-for-service/generative-ai-tools/test-date-and-results/xogpt-answer-generation-v1.0.xlsx) for full details.
See [Test Data and Results v1](https://raw.githubusercontent.com/Koredotcom/docs-v2/refs/heads/main/ai-for-service/generative-ai-tools/test-date-and-results/xogpt-answer-generation-v1.0.xlsx) for full details.