> ## Documentation Index
> Fetch the complete documentation index at: https://koreai.mintlify.site/llms.txt
> Use this file to discover all available pages before exploring further.
# XO GPT Conversation Summarization Model
[Back to XO GPT Model Specifications](/ai-for-service/generative-ai-tools/xo-gpt-module#xo-gpt-model-specifications)
The XO GPT Conversation Summarization model generates concise, context-aware summaries of agent-customer interactions. It uses abstractive summarization, context analysis, and sentiment detection to transform lengthy dialogues into actionable insights.
***
## Challenges with Commercial Models
| Challenge | Impact |
| -------------------------- | ----------------------------------------------------------------------------------------------- |
| **Latency** | High processing times affect user experience in real-time or high-volume scenarios. |
| **Cost** | Per-request pricing scales poorly for large deployments. |
| **Data Governance** | Sending conversations to external models raises privacy and security concerns. |
| **Lack of Customization** | General-purpose models aren't tuned for specific industries or use cases. |
| **Limited Control** | Minimal ability to correct or refine model behavior for incorrect outputs. |
| **Compliance Constraints** | Some industries have regulatory requirements that commercial LLM providers don't fully support. |
***
## Key Assumptions
* Designed for text-based conversations only.
* Assumes structured conversational data with clear speaker delineation.
***
## Benefits
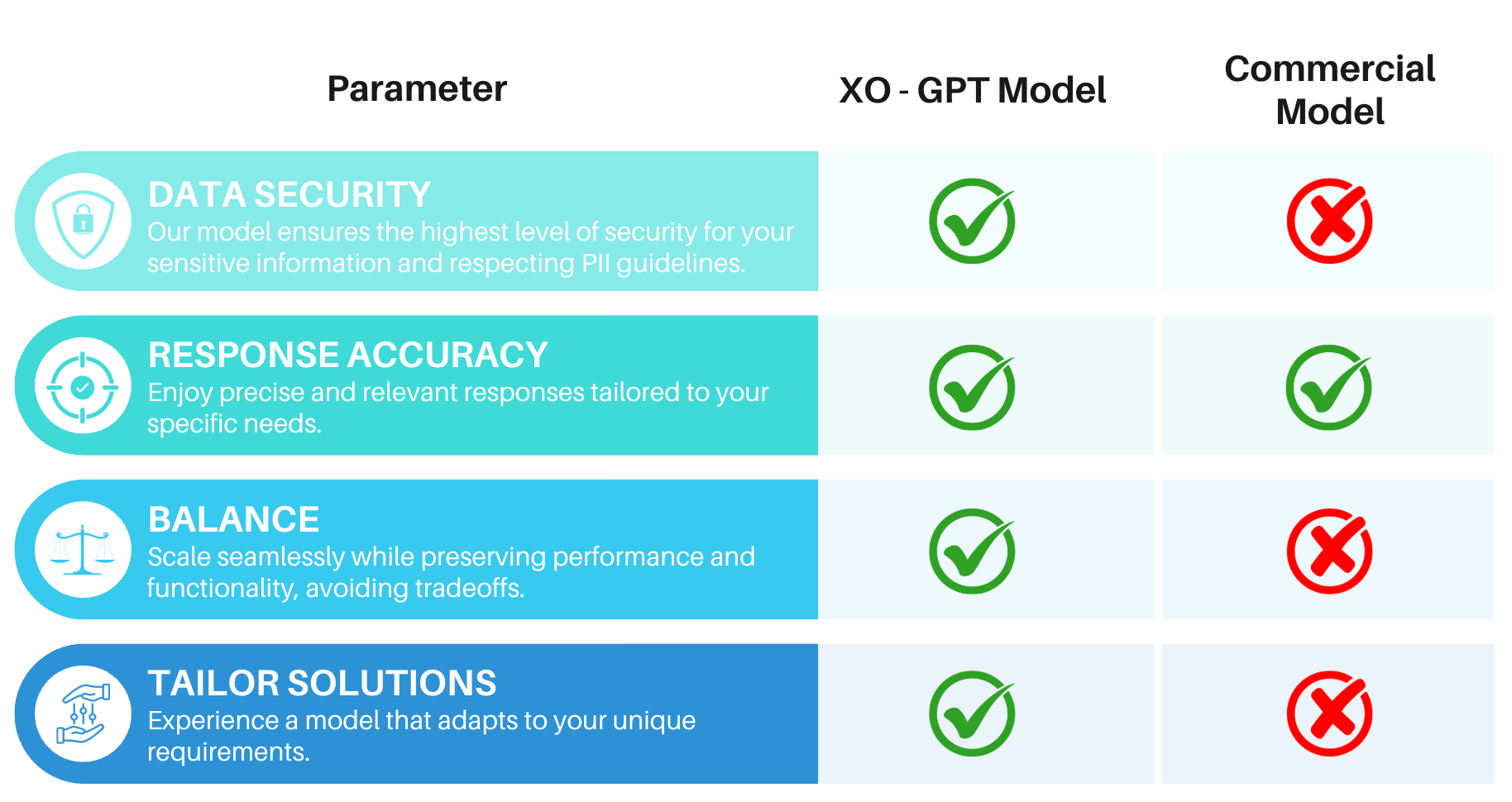 ### Consistent and Accurate
Delivers precise, contextually relevant summaries for conversation transcripts. See [Model Benchmarks](#model-benchmarks) for latency and accuracy metrics.
### Cost-Effective
For Enterprise Tier customers, XO GPT eliminates commercial model usage costs. Example comparison (250 input tokens/conversation, 1,000 daily summaries, 120 tokens/summary):
| Model | Input \$/MTok | Output \$/MTok | Input \$/Year | Output \$/Year | Total \$/Year |
| ----------- | ------------- | -------------- | ------------- | -------------- | ------------- |
| GPT-4 Turbo | \$30 | \$60 | \$2,738 | \$2,628 | \$5,366 |
| GPT-4 | \$10 | \$30 | \$913 | \$1,314 | \$2,227 |
| GPT-4o Mini | \$0.15 | \$0.60 | \$13.69 | \$26.28 | \$39.97 |
### Enhanced Security
No client or user data is used for model retraining.
**Guardrails:** Content moderation, behavioral guidelines, response oversight, input validation, and usage controls.
**AI Safety:** Ethical guidelines, bias monitoring, transparency, and continuous improvement.
Performance, features, and language support may vary by implementation. Test thoroughly in your environment before production use.
***
## Use Cases
| Domain | Use Case |
| -------------------- | ------------------------------------------------------------------------------------------------- |
| Healthcare | Summarize patient inquiries about symptoms, medications, and follow-up instructions. |
| Banking | Summarize conversations about account issues, transaction disputes, or loan applications. |
| E-commerce | Summarize inquiries about product availability, order status, returns, and refunds. |
| Insurance | Summarize policyholder interactions about claims, policy updates, and coverage questions. |
| IT Support | Summarize troubleshooting steps, error reports, and resolutions for technical issues. |
| Telecommunications | Summarize complaints and service requests about network issues, billing errors, and plan changes. |
| Travel & Hospitality | Summarize queries about booking modifications, cancellations, and special requests. |
| Retail | Summarize interactions about store policies, promotions, and product exchanges. |
| Education | Summarize inquiries about course enrollments, schedules, and academic records. |
| Utilities | Summarize communications about service outages, bill inquiries, and usage reports. |
***
## Sample Output
**Conversation:**
```
App: Hello! How can I help you today?
Customer: I need to check the status of my order.
App: Sure! Please provide your order reference number.
Customer: It's 12345-67890.
[Identity verified; order confirmed shipping within 48 hours]
Customer: Yes, I want to speak with an agent.
Agent: Hi, this is John from XYZ Support. How can I assist you today?
Customer: I wanted to confirm the shipping address on my order.
Agent: The address on file is 123 Elm Street, Springfield, IL.
Customer: That's correct. Thanks!
```
**Generated Summary:**
> The customer contacted support to check the status of their order. The AI Agent verified the customer's identity and informed them their order would ship within 48 hours. The customer then requested to speak with an agent to verify their shipping address. The agent confirmed the address on file was correct. The conversation ended with the customer satisfied.
### Consistent and Accurate
Delivers precise, contextually relevant summaries for conversation transcripts. See [Model Benchmarks](#model-benchmarks) for latency and accuracy metrics.
### Cost-Effective
For Enterprise Tier customers, XO GPT eliminates commercial model usage costs. Example comparison (250 input tokens/conversation, 1,000 daily summaries, 120 tokens/summary):
| Model | Input \$/MTok | Output \$/MTok | Input \$/Year | Output \$/Year | Total \$/Year |
| ----------- | ------------- | -------------- | ------------- | -------------- | ------------- |
| GPT-4 Turbo | \$30 | \$60 | \$2,738 | \$2,628 | \$5,366 |
| GPT-4 | \$10 | \$30 | \$913 | \$1,314 | \$2,227 |
| GPT-4o Mini | \$0.15 | \$0.60 | \$13.69 | \$26.28 | \$39.97 |
### Enhanced Security
No client or user data is used for model retraining.
**Guardrails:** Content moderation, behavioral guidelines, response oversight, input validation, and usage controls.
**AI Safety:** Ethical guidelines, bias monitoring, transparency, and continuous improvement.
Performance, features, and language support may vary by implementation. Test thoroughly in your environment before production use.
***
## Use Cases
| Domain | Use Case |
| -------------------- | ------------------------------------------------------------------------------------------------- |
| Healthcare | Summarize patient inquiries about symptoms, medications, and follow-up instructions. |
| Banking | Summarize conversations about account issues, transaction disputes, or loan applications. |
| E-commerce | Summarize inquiries about product availability, order status, returns, and refunds. |
| Insurance | Summarize policyholder interactions about claims, policy updates, and coverage questions. |
| IT Support | Summarize troubleshooting steps, error reports, and resolutions for technical issues. |
| Telecommunications | Summarize complaints and service requests about network issues, billing errors, and plan changes. |
| Travel & Hospitality | Summarize queries about booking modifications, cancellations, and special requests. |
| Retail | Summarize interactions about store policies, promotions, and product exchanges. |
| Education | Summarize inquiries about course enrollments, schedules, and academic records. |
| Utilities | Summarize communications about service outages, bill inquiries, and usage reports. |
***
## Sample Output
**Conversation:**
```
App: Hello! How can I help you today?
Customer: I need to check the status of my order.
App: Sure! Please provide your order reference number.
Customer: It's 12345-67890.
[Identity verified; order confirmed shipping within 48 hours]
Customer: Yes, I want to speak with an agent.
Agent: Hi, this is John from XYZ Support. How can I assist you today?
Customer: I wanted to confirm the shipping address on my order.
Agent: The address on file is 123 Elm Street, Springfield, IL.
Customer: That's correct. Thanks!
```
**Generated Summary:**
> The customer contacted support to check the status of their order. The AI Agent verified the customer's identity and informed them their order would ship within 48 hours. The customer then requested to speak with an agent to verify their shipping address. The agent confirmed the address on file was correct. The conversation ended with the customer satisfied.
 ***
## Model Building Process
See [Model Building Process](/ai-for-service/generative-ai-tools/xogpt-model-specifications#model-building-process).
***
## Model Benchmarks
| Version | Accuracy | TPS | Latency (s) | Benchmark | Test Data |
| ------- | -------- | --- | ----------- | ------------------------------------ | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| v2.0 | 100% | 71 | 2.00 | [Summary v2](#benchmarks-summary-v2) | [Results v2](https://raw.githubusercontent.com/Koredotcom/docs-v2/refs/heads/main/ai-for-service/generative-ai-tools/test-date-and-results/xogpt-conversation-summarization-v2.0.xlsx) |
| v1.0 | 98% | 40 | 3.04 | [Summary v1](#benchmarks-summary-v1) | [Results v1](https://raw.githubusercontent.com/Koredotcom/docs-v2/refs/heads/main/ai-for-service/generative-ai-tools/test-date-and-results/xogpt-conversation-summarization-v1.0.xlsx) |
***
## Version 2.0
### Model Choice
Base model: [Mistral 7B Instruct v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2)
| Base Model | Developer | Language | Release Date | Status | Knowledge Cutoff |
| ------------------------ | ---------- | ------------- | -------------- | ------ | ---------------- |
| Mistral 7B Instruct v0.2 | Mistral AI | Multi-lingual | September 2024 | Static | September 2024 |
### Fine-Tuning Parameters
| Parameter | Description | Value |
| ------------------- | ---------------------------------------- | ------------------------------------------------------------------------------- |
| Fine-Tuning Type | Method used | peft-qlora |
| Quantization | Bits for loading parameters | 4-bit |
| Rank | Number of trainable parameters | 32 |
| LoRA Dropout | Prevents co-adaptation in neural network | 0.05 |
| LoRA Alpha | Scaling factor | — |
| Learning Rate | Rate toward loss minimum | 2e-4 (0.0002) |
| Batch Size | Examples per training step | 2 |
| Epochs | Passes over training data | 3 |
| Max Sequence Length | Maximum input length | 32768 |
| Optimizer | Optimization algorithm | paged\_adamw\_8bit |
| Task Type | LoRA task type | CAUSAL\_LM |
| Targeted Modules | Layers where LoRA is applied | `["up_proj", "o_proj", "down_proj", "gate_proj", "q_proj", "k_proj", "v_proj"]` |
### General Parameters
Infrastructure: 2× A10 GPUs. Requires an Agent AI License.
| Parameter | Description | Value |
| ------------------- | -------------------------- | ------------------ |
| Learning Rate | Rate toward loss minimum | 2e-4 (0.0002) |
| Batch Size | Examples per training step | 2 |
| Epochs | Passes over training data | 3 |
| Max Sequence Length | Maximum input length | 32768 |
| Optimizer | Optimization algorithm | paged\_adamw\_8bit |
### AWQ Model Quantization
| Parameter | Description | Value |
| ----------------------- | --------------------------------------------------- | ----------------------------- |
| Zero Point | Include zero-point for better weight representation | True |
| Quantization Group Size | Weight group size | 128 |
| Weight Precision | Bits for weight representation | 4 |
| Quantization Version | AWQ version for GEMM operations | "GEMM" |
| Computation Data Type | Data type for inference | torch.float16 |
| Model Loading | Reduced CPU memory usage | `{"low_cpu_mem_usage": True}` |
| Tokenizer Loading | Remote code compatibility | `trust_remote_code=True` |
### Benchmarks Summary v2
Comparison models: LLama-8B, GPT-4, Claude 3 Sonnet.
***
## Model Building Process
See [Model Building Process](/ai-for-service/generative-ai-tools/xogpt-model-specifications#model-building-process).
***
## Model Benchmarks
| Version | Accuracy | TPS | Latency (s) | Benchmark | Test Data |
| ------- | -------- | --- | ----------- | ------------------------------------ | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| v2.0 | 100% | 71 | 2.00 | [Summary v2](#benchmarks-summary-v2) | [Results v2](https://raw.githubusercontent.com/Koredotcom/docs-v2/refs/heads/main/ai-for-service/generative-ai-tools/test-date-and-results/xogpt-conversation-summarization-v2.0.xlsx) |
| v1.0 | 98% | 40 | 3.04 | [Summary v1](#benchmarks-summary-v1) | [Results v1](https://raw.githubusercontent.com/Koredotcom/docs-v2/refs/heads/main/ai-for-service/generative-ai-tools/test-date-and-results/xogpt-conversation-summarization-v1.0.xlsx) |
***
## Version 2.0
### Model Choice
Base model: [Mistral 7B Instruct v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2)
| Base Model | Developer | Language | Release Date | Status | Knowledge Cutoff |
| ------------------------ | ---------- | ------------- | -------------- | ------ | ---------------- |
| Mistral 7B Instruct v0.2 | Mistral AI | Multi-lingual | September 2024 | Static | September 2024 |
### Fine-Tuning Parameters
| Parameter | Description | Value |
| ------------------- | ---------------------------------------- | ------------------------------------------------------------------------------- |
| Fine-Tuning Type | Method used | peft-qlora |
| Quantization | Bits for loading parameters | 4-bit |
| Rank | Number of trainable parameters | 32 |
| LoRA Dropout | Prevents co-adaptation in neural network | 0.05 |
| LoRA Alpha | Scaling factor | — |
| Learning Rate | Rate toward loss minimum | 2e-4 (0.0002) |
| Batch Size | Examples per training step | 2 |
| Epochs | Passes over training data | 3 |
| Max Sequence Length | Maximum input length | 32768 |
| Optimizer | Optimization algorithm | paged\_adamw\_8bit |
| Task Type | LoRA task type | CAUSAL\_LM |
| Targeted Modules | Layers where LoRA is applied | `["up_proj", "o_proj", "down_proj", "gate_proj", "q_proj", "k_proj", "v_proj"]` |
### General Parameters
Infrastructure: 2× A10 GPUs. Requires an Agent AI License.
| Parameter | Description | Value |
| ------------------- | -------------------------- | ------------------ |
| Learning Rate | Rate toward loss minimum | 2e-4 (0.0002) |
| Batch Size | Examples per training step | 2 |
| Epochs | Passes over training data | 3 |
| Max Sequence Length | Maximum input length | 32768 |
| Optimizer | Optimization algorithm | paged\_adamw\_8bit |
### AWQ Model Quantization
| Parameter | Description | Value |
| ----------------------- | --------------------------------------------------- | ----------------------------- |
| Zero Point | Include zero-point for better weight representation | True |
| Quantization Group Size | Weight group size | 128 |
| Weight Precision | Bits for weight representation | 4 |
| Quantization Version | AWQ version for GEMM operations | "GEMM" |
| Computation Data Type | Data type for inference | torch.float16 |
| Model Loading | Reduced CPU memory usage | `{"low_cpu_mem_usage": True}` |
| Tokenizer Loading | Remote code compatibility | `trust_remote_code=True` |
### Benchmarks Summary v2
Comparison models: LLama-8B, GPT-4, Claude 3 Sonnet.
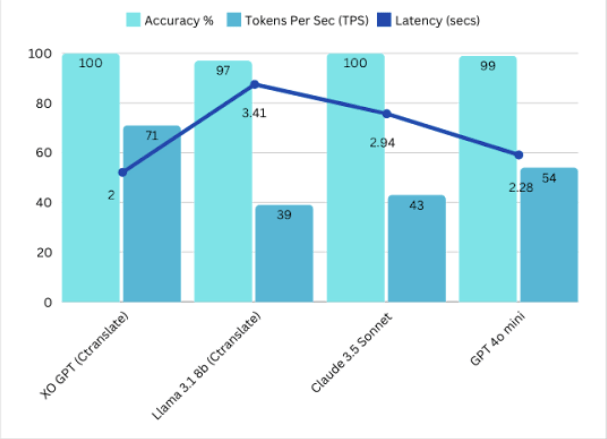 XO GPT achieved an outstanding overall score, positioning it alongside Llama and ahead of Sonnet and GPT-4. It delivers strong results across accuracy, fluency, and robustness in English, French, German, Japanese, Turkish, and Spanish.
See [Test Data and Results v2](https://raw.githubusercontent.com/Koredotcom/docs-v2/refs/heads/main/ai-for-service/generative-ai-tools/test-date-and-results/xogpt-conversation-summarization-v2.0.xlsx) for full details.
***
## Version 1.0
### Model Choice
Base model: [Mistral 7B Instruct v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2)
| Base Model | Developer | Language | Release Date | Status | Knowledge Cutoff |
| ------------------------ | ---------- | ------------- | ------------ | ------ | ---------------- |
| Mistral 7B Instruct v0.2 | Mistral AI | Multi-lingual | March 2024 | Static | September 2024 |
### Fine-Tuning Parameters
| Parameter | Description | Value |
| ------------------- | ---------------------------------------- | ------------------ |
| Fine-Tuning Type | Method used | peft-qlora |
| Quantization | Bits for loading parameters | 4-bit |
| Rank | Number of trainable parameters | 32 |
| LoRA Dropout | Prevents co-adaptation in neural network | 0.05 |
| Learning Rate | Rate toward loss minimum | 1e-3 (0.001) |
| Batch Size | Examples per training step | 2 |
| Epochs | Passes over training data | 4 |
| Max Sequence Length | Maximum input length | — |
| Optimizer | Optimization algorithm | paged\_adamw\_8bit |
| Task Type | LoRA task type | CAUSAL\_LM |
### General Parameters
Infrastructure: 2× A10 GPUs. Requires an Agent AI License.
| Parameter | Description | Value |
| ------------------- | -------------------------- | ------------------ |
| Learning Rate | Rate toward loss minimum | 1e-3 (0.001) |
| Batch Size | Examples per training step | 2 |
| Epochs | Passes over training data | 4 |
| Max Sequence Length | Maximum input length | 32768 |
| Optimizer | Optimization algorithm | paged\_adamw\_8bit |
### Benchmarks Summary v1
Comparison models: Llama 3 8B (Ctranslate), Sonnet 3.5, GPT-4o.
XO GPT achieved an outstanding overall score, positioning it alongside Llama and ahead of Sonnet and GPT-4. It delivers strong results across accuracy, fluency, and robustness in English, French, German, Japanese, Turkish, and Spanish.
See [Test Data and Results v2](https://raw.githubusercontent.com/Koredotcom/docs-v2/refs/heads/main/ai-for-service/generative-ai-tools/test-date-and-results/xogpt-conversation-summarization-v2.0.xlsx) for full details.
***
## Version 1.0
### Model Choice
Base model: [Mistral 7B Instruct v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2)
| Base Model | Developer | Language | Release Date | Status | Knowledge Cutoff |
| ------------------------ | ---------- | ------------- | ------------ | ------ | ---------------- |
| Mistral 7B Instruct v0.2 | Mistral AI | Multi-lingual | March 2024 | Static | September 2024 |
### Fine-Tuning Parameters
| Parameter | Description | Value |
| ------------------- | ---------------------------------------- | ------------------ |
| Fine-Tuning Type | Method used | peft-qlora |
| Quantization | Bits for loading parameters | 4-bit |
| Rank | Number of trainable parameters | 32 |
| LoRA Dropout | Prevents co-adaptation in neural network | 0.05 |
| Learning Rate | Rate toward loss minimum | 1e-3 (0.001) |
| Batch Size | Examples per training step | 2 |
| Epochs | Passes over training data | 4 |
| Max Sequence Length | Maximum input length | — |
| Optimizer | Optimization algorithm | paged\_adamw\_8bit |
| Task Type | LoRA task type | CAUSAL\_LM |
### General Parameters
Infrastructure: 2× A10 GPUs. Requires an Agent AI License.
| Parameter | Description | Value |
| ------------------- | -------------------------- | ------------------ |
| Learning Rate | Rate toward loss minimum | 1e-3 (0.001) |
| Batch Size | Examples per training step | 2 |
| Epochs | Passes over training data | 4 |
| Max Sequence Length | Maximum input length | 32768 |
| Optimizer | Optimization algorithm | paged\_adamw\_8bit |
### Benchmarks Summary v1
Comparison models: Llama 3 8B (Ctranslate), Sonnet 3.5, GPT-4o.
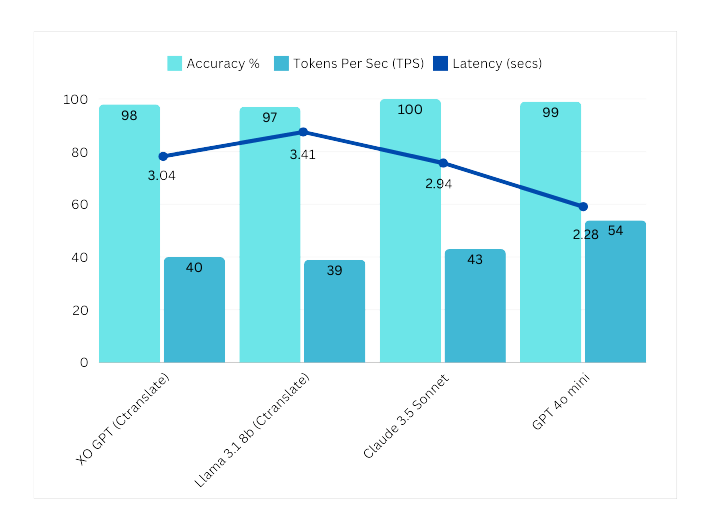 XO GPT demonstrates strong performance in English, French, German, and Spanish, with notable results in bias detection, sentiment analysis, and negation detection.
See [Test Data and Results v1](https://raw.githubusercontent.com/Koredotcom/docs-v2/refs/heads/main/ai-for-service/generative-ai-tools/test-date-and-results/xogpt-conversation-summarization-v1.0.xlsx) for full details.
XO GPT demonstrates strong performance in English, French, German, and Spanish, with notable results in bias detection, sentiment analysis, and negation detection.
See [Test Data and Results v1](https://raw.githubusercontent.com/Koredotcom/docs-v2/refs/heads/main/ai-for-service/generative-ai-tools/test-date-and-results/xogpt-conversation-summarization-v1.0.xlsx) for full details.