> ## Documentation Index
> Fetch the complete documentation index at: https://koreai.mintlify.app/llms.txt
> Use this file to discover all available pages before exploring further.
# Evaluation Metrics
Evaluation Metrics let supervisors define and monitor performance indicators for measuring the quality of agent-customer interactions. The system supports six measurement types, each designed for specific evaluation needs using AI-driven analysis or rule-based methods.
## Key Benefits
| Benefit | Description |
| --------------------------- | ------------------------------------------------------------------- |
| **AI-powered intelligence** | GenAI-based adherence reduces dependency on large training datasets |
| **Comprehensive coverage** | Six measurement types address diverse evaluation scenarios |
| **Multilingual support** | Enhanced support across languages and interactions |
| **Automated QA** | Reduces manual review workload through intelligent analysis |
| **Real-time validation** | API integration ensures data accuracy and compliance |
| **Flexible configuration** | Static and dynamic evaluation options |
## Access Evaluation Metrics
Navigate to **Quality AI** > **CONFIGURE** > **Evaluation Forms** > **Evaluation Metrics**.
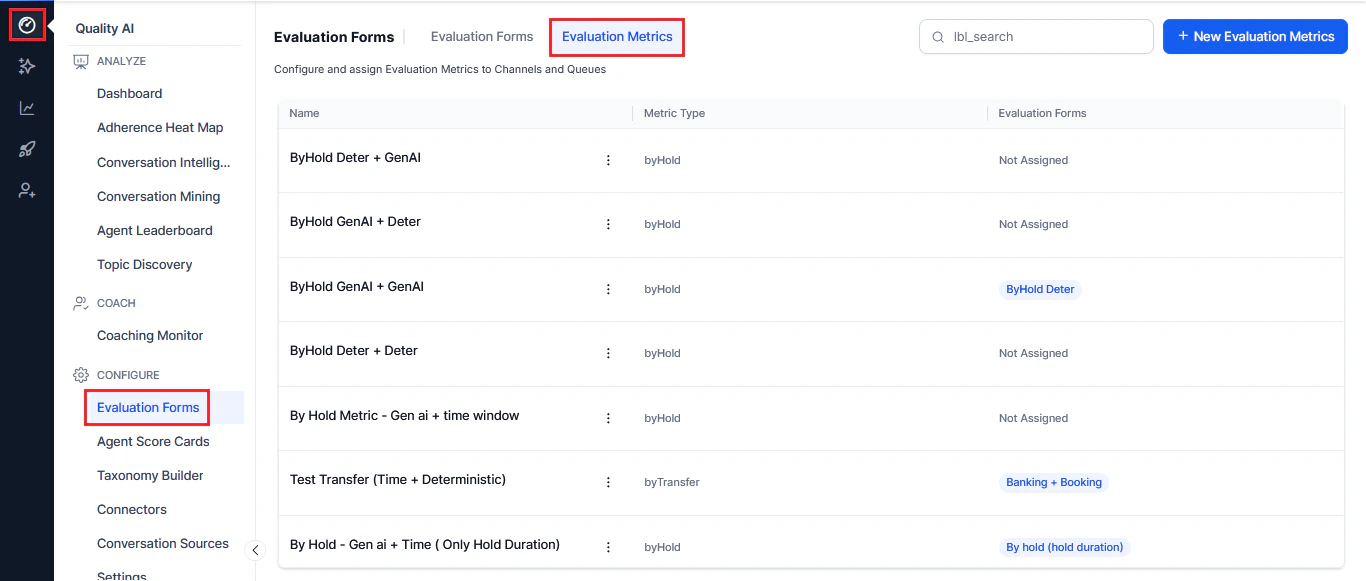 The dashboard shows:
| Column | Description |
| -------------------------- | ---------------------------- |
| **Name** | Metric name |
| **Metric Type** | Measurement type |
| **Evaluation Forms** | Associated evaluation forms |
| **Ellipsis icon (⋮)** | Edit and delete options |
| **Search** | Quick search to find metrics |
| **New Evaluation Metrics** | Button to create new metrics |
***
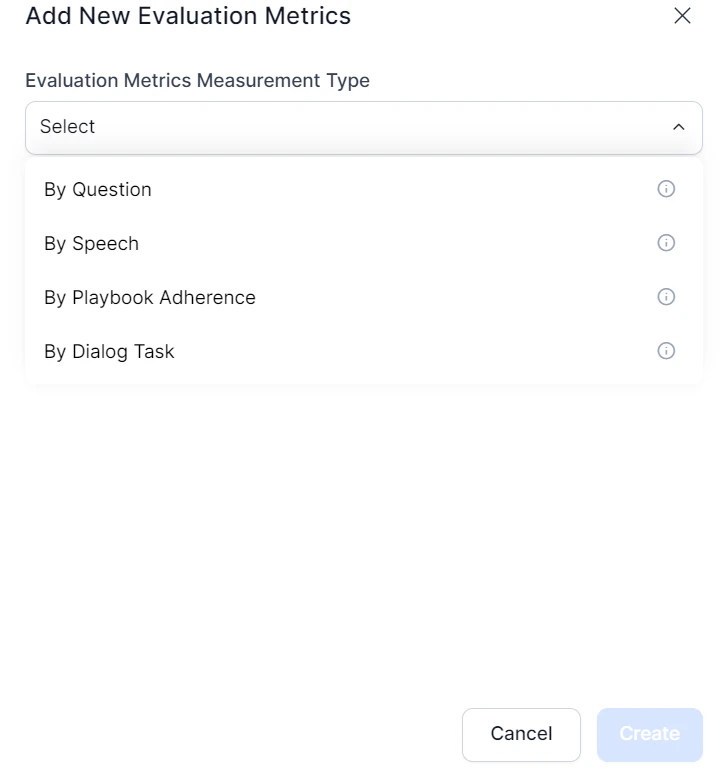
## Create a New Evaluation Metric
1. Select the **Evaluation Metrics** tab.
2. Select **+ New Evaluation Metric**.
3. Choose and configure your measurement type.
The dashboard shows:
| Column | Description |
| -------------------------- | ---------------------------- |
| **Name** | Metric name |
| **Metric Type** | Measurement type |
| **Evaluation Forms** | Associated evaluation forms |
| **Ellipsis icon (⋮)** | Edit and delete options |
| **Search** | Quick search to find metrics |
| **New Evaluation Metrics** | Button to create new metrics |
***
## Create a New Evaluation Metric
1. Select the **Evaluation Metrics** tab.
2. Select **+ New Evaluation Metric**.
3. Choose and configure your measurement type.
 ### Key Configuration Options
| Option | Description |
| ----------------------- | ------------------------------------------------------- |
| **Metric name** | Descriptive identifier for future reference |
| **Language** | Multi-language support configuration |
| **Evaluation question** | Reference prompt for audits and interaction reviews |
| **Adherence type** | Static (universal) or Dynamic (trigger-based) detection |
### Detection Methods
| Feature | GenAI-Based | Deterministic |
| --------------- | ---------------------------- | ---------------------------- |
| **Mechanism** | LLM contextual understanding | Semantic similarity matching |
| **Training** | Zero-shot prompts | Sample utterance training |
| **Flexibility** | High contextual adaptation | Precise pattern recognition |
| **Setup** | Description-based | Utterance-based |
***
## Measurement Types
### By Question
Evaluates adherence to specific questions asked or answered during interactions.
**Key features:**
* **Static Adherence** — applies to all conversations
* **Dynamic Adherence** — conditional evaluation triggered by specific events
* **GenAI Detection** — contextual understanding with no training samples required
* **Deterministic Detection** — semantic matching against predefined patterns
* **Flexible thresholds** — set different similarity scores per use case
**Common use cases:** Script adherence, greeting compliance, policy verification, response quality.
For full configuration details, see [By Question](../configure/evaluation-criteria/metrics-measurement-types/by-question.mdx).
### By Speech
Analyzes speech characteristics during voice interactions.
**Key features:**
* **Crosstalk** — detects overlapping speech with configurable thresholds
* **Dead Air** — monitors silence periods (configurable duration)
* **Speaking Rate** — tracks Words Per Minute (WPM)
**Use cases:** Voice quality, conversation flow analysis, speaking pace optimization.
For full configuration details, see [By Speech](../configure/evaluation-criteria/metrics-measurement-types/by-speech.mdx).
### By Value
Verifies customer-specific information shared by an agent against trusted data sources.
**Key features:**
* **API integration** — real-time verification with CRM and external systems
* **Business rules engine** — five rule types (first/last value, negotiated, strict matching, custom)
* **Compliance tracking** — detects deviations from expected values
* **Audit trails** — logs validation results for supervisory review
**Use cases:** Pricing accuracy, interest rate verification, account balance confirmation, compliance validation.
For full configuration details, see [By Value](../configure/evaluation-criteria/metrics-measurement-types/by-value.mdx).
### By Dialog Task
Assesses completion and quality of specific tasks or workflows within a conversation.
**Key features:**
* **Dialog agent selection** — choose which dialog agent to evaluate
* **Evaluation scope** — entire conversation or time-bound segment
* **Time parameters** — configurable in seconds (voice) or message count (chat)
**Use cases:** Workflow adherence, task completion verification, dialog flow optimization.
For full configuration details, see [By Dialog Task](../configure/evaluation-criteria/metrics-measurement-types/by-dialog-task.mdx).
### By Playbook Adherence
Measures how well interactions follow predefined playbooks or procedures.
**Key features:**
* **Entire Playbook** — assesses adherence across all playbook components
* **Specific Steps** — targets evaluation at specific stages or steps
* **Percentage thresholds** — define minimum adherence levels required
**Use cases:** Process compliance, procedure adherence, enforcement of standards.
For full configuration details, see [By Playbook Adherence](../configure/evaluation-criteria/metrics-measurement-types/by-playbook-adherence.mdx).
### By AI Agent
Uses AI Agents for sophisticated, multi-step evaluations with autonomous decision-making.
**Key features:**
* **Complex analysis** — multi-step reasoning across conversation elements
* **Domain expertise** — supports specialized evaluation contexts (compliance, technical support)
* **Contextual understanding** — nuanced evaluation requiring full conversation context
* **Advanced decision-making** — goes beyond pattern matching for judgment calls
**Use cases:** Complex compliance assessments, technical troubleshooting evaluation, sophisticated quality analysis.
For full configuration details, see [By AI Agent](../configure/evaluation-criteria/metrics-measurement-types/by-ai-agent.mdx).
***
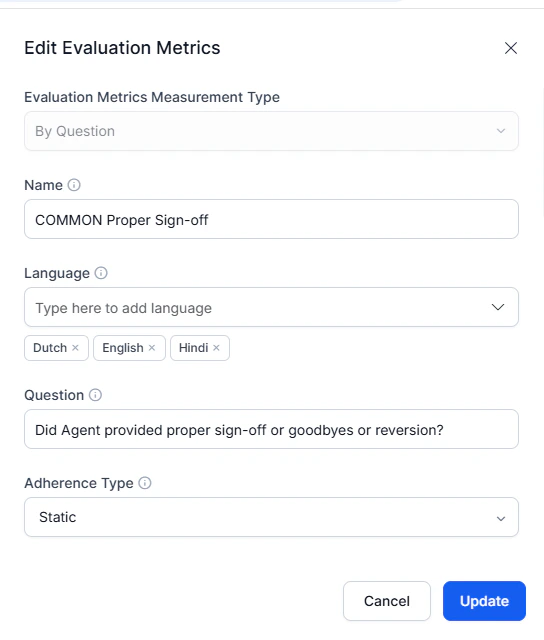
## Edit or Delete Evaluation Metrics
1. Search for and select the metric.
2. Select the three-dot menu (⋮) next to the metric name.
3. Select **Edit** to modify or **Delete** to remove.
4. For percentage-based metrics, adjust weights so they total 100%.
5. Select **Update** to save changes.
### Key Configuration Options
| Option | Description |
| ----------------------- | ------------------------------------------------------- |
| **Metric name** | Descriptive identifier for future reference |
| **Language** | Multi-language support configuration |
| **Evaluation question** | Reference prompt for audits and interaction reviews |
| **Adherence type** | Static (universal) or Dynamic (trigger-based) detection |
### Detection Methods
| Feature | GenAI-Based | Deterministic |
| --------------- | ---------------------------- | ---------------------------- |
| **Mechanism** | LLM contextual understanding | Semantic similarity matching |
| **Training** | Zero-shot prompts | Sample utterance training |
| **Flexibility** | High contextual adaptation | Precise pattern recognition |
| **Setup** | Description-based | Utterance-based |
***
## Measurement Types
### By Question
Evaluates adherence to specific questions asked or answered during interactions.
**Key features:**
* **Static Adherence** — applies to all conversations
* **Dynamic Adherence** — conditional evaluation triggered by specific events
* **GenAI Detection** — contextual understanding with no training samples required
* **Deterministic Detection** — semantic matching against predefined patterns
* **Flexible thresholds** — set different similarity scores per use case
**Common use cases:** Script adherence, greeting compliance, policy verification, response quality.
For full configuration details, see [By Question](../configure/evaluation-criteria/metrics-measurement-types/by-question.mdx).
### By Speech
Analyzes speech characteristics during voice interactions.
**Key features:**
* **Crosstalk** — detects overlapping speech with configurable thresholds
* **Dead Air** — monitors silence periods (configurable duration)
* **Speaking Rate** — tracks Words Per Minute (WPM)
**Use cases:** Voice quality, conversation flow analysis, speaking pace optimization.
For full configuration details, see [By Speech](../configure/evaluation-criteria/metrics-measurement-types/by-speech.mdx).
### By Value
Verifies customer-specific information shared by an agent against trusted data sources.
**Key features:**
* **API integration** — real-time verification with CRM and external systems
* **Business rules engine** — five rule types (first/last value, negotiated, strict matching, custom)
* **Compliance tracking** — detects deviations from expected values
* **Audit trails** — logs validation results for supervisory review
**Use cases:** Pricing accuracy, interest rate verification, account balance confirmation, compliance validation.
For full configuration details, see [By Value](../configure/evaluation-criteria/metrics-measurement-types/by-value.mdx).
### By Dialog Task
Assesses completion and quality of specific tasks or workflows within a conversation.
**Key features:**
* **Dialog agent selection** — choose which dialog agent to evaluate
* **Evaluation scope** — entire conversation or time-bound segment
* **Time parameters** — configurable in seconds (voice) or message count (chat)
**Use cases:** Workflow adherence, task completion verification, dialog flow optimization.
For full configuration details, see [By Dialog Task](../configure/evaluation-criteria/metrics-measurement-types/by-dialog-task.mdx).
### By Playbook Adherence
Measures how well interactions follow predefined playbooks or procedures.
**Key features:**
* **Entire Playbook** — assesses adherence across all playbook components
* **Specific Steps** — targets evaluation at specific stages or steps
* **Percentage thresholds** — define minimum adherence levels required
**Use cases:** Process compliance, procedure adherence, enforcement of standards.
For full configuration details, see [By Playbook Adherence](../configure/evaluation-criteria/metrics-measurement-types/by-playbook-adherence.mdx).
### By AI Agent
Uses AI Agents for sophisticated, multi-step evaluations with autonomous decision-making.
**Key features:**
* **Complex analysis** — multi-step reasoning across conversation elements
* **Domain expertise** — supports specialized evaluation contexts (compliance, technical support)
* **Contextual understanding** — nuanced evaluation requiring full conversation context
* **Advanced decision-making** — goes beyond pattern matching for judgment calls
**Use cases:** Complex compliance assessments, technical troubleshooting evaluation, sophisticated quality analysis.
For full configuration details, see [By AI Agent](../configure/evaluation-criteria/metrics-measurement-types/by-ai-agent.mdx).
***
## Edit or Delete Evaluation Metrics
1. Search for and select the metric.
2. Select the three-dot menu (⋮) next to the metric name.
3. Select **Edit** to modify or **Delete** to remove.
4. For percentage-based metrics, adjust weights so they total 100%.
5. Select **Update** to save changes.
 ***
Built with [Mintlify](https://mintlify.com).
***
Built with [Mintlify](https://mintlify.com).