

Current Capabilities
- Voice: Supports the Voice Gateway channel for GenAI features including Agent Node, with Deepgram as the supported TTS engine.
- Chat: Delivers real-time LLM response streaming for Web/Mobile SDK and Microsoft Teams channels. Agent Node and Prompt Node stream responses token-by-token.
- Models: Integrates with OpenAI and Azure OpenAI out of the box. Custom prompts support other streaming-capable LLMs.
- Node-level activation: Streaming activates when a streaming prompt is selected at the node level, even if the feature-level prompt doesn’t use streaming.
- V1 Custom JavaScript Prompts: Supports tool calling and streaming as separate capabilities only—not simultaneously.
- V2 Custom JavaScript Prompts: Supports both tool calling and streaming together using the OpenAI/Azure OpenAI response format.
Benefits
Use Cases
Enable Streaming
Use a Default Streaming Prompt
The Platform provides default streaming prompts for Agent Node and Prompt Node for OpenAI models. Go to Generative AI Tools > GenAI Features and select the default-streaming prompt for the required feature.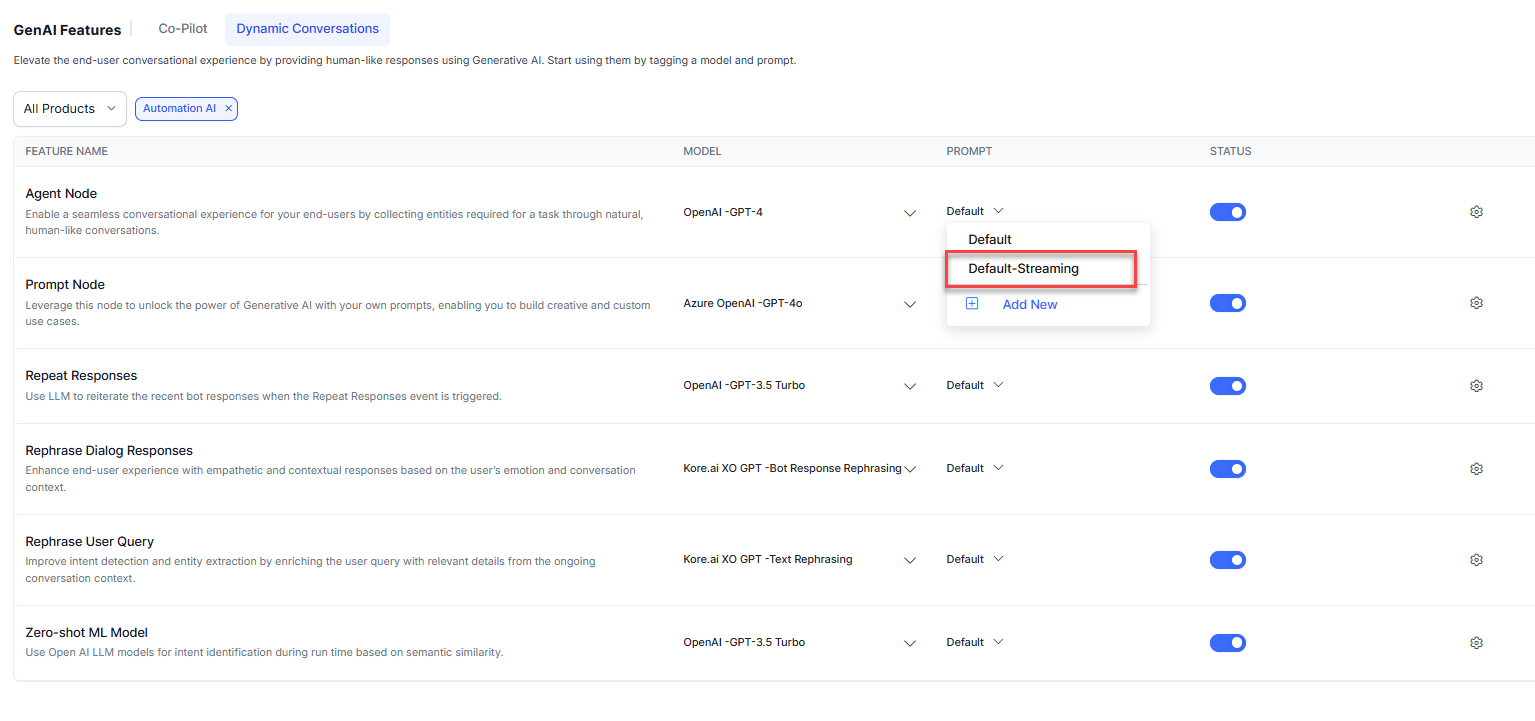
Create a Custom Streaming Prompt
See How to Add a Custom Prompt and enable the Stream Response toggle. The streamed response must follow this format:- Add the required stream parameter to your custom prompt (for example,
"stream": truefor OpenAI/Azure OpenAI). - The saved prompt appears with a “stream” tag in the Prompts Library.
- Enabling streaming disables: Exit Scenario, AI Agent Response, Collected Entities, and Tool Call Request (for Agent Node).
Performance Benchmarks
Key insights:
- Output < 100 tokens: 80-85% time reduction.
- Output 100-600 tokens: 97-98% time reduction.
- Output > 600 tokens: 98-99% time reduction.
- Output quality variance is minimal (≤2.5%), ensuring task reliability.
These benchmarks were conducted under specific scenarios. Performance varies by environment. Conduct your own testing before enabling streaming in production.
Analytics
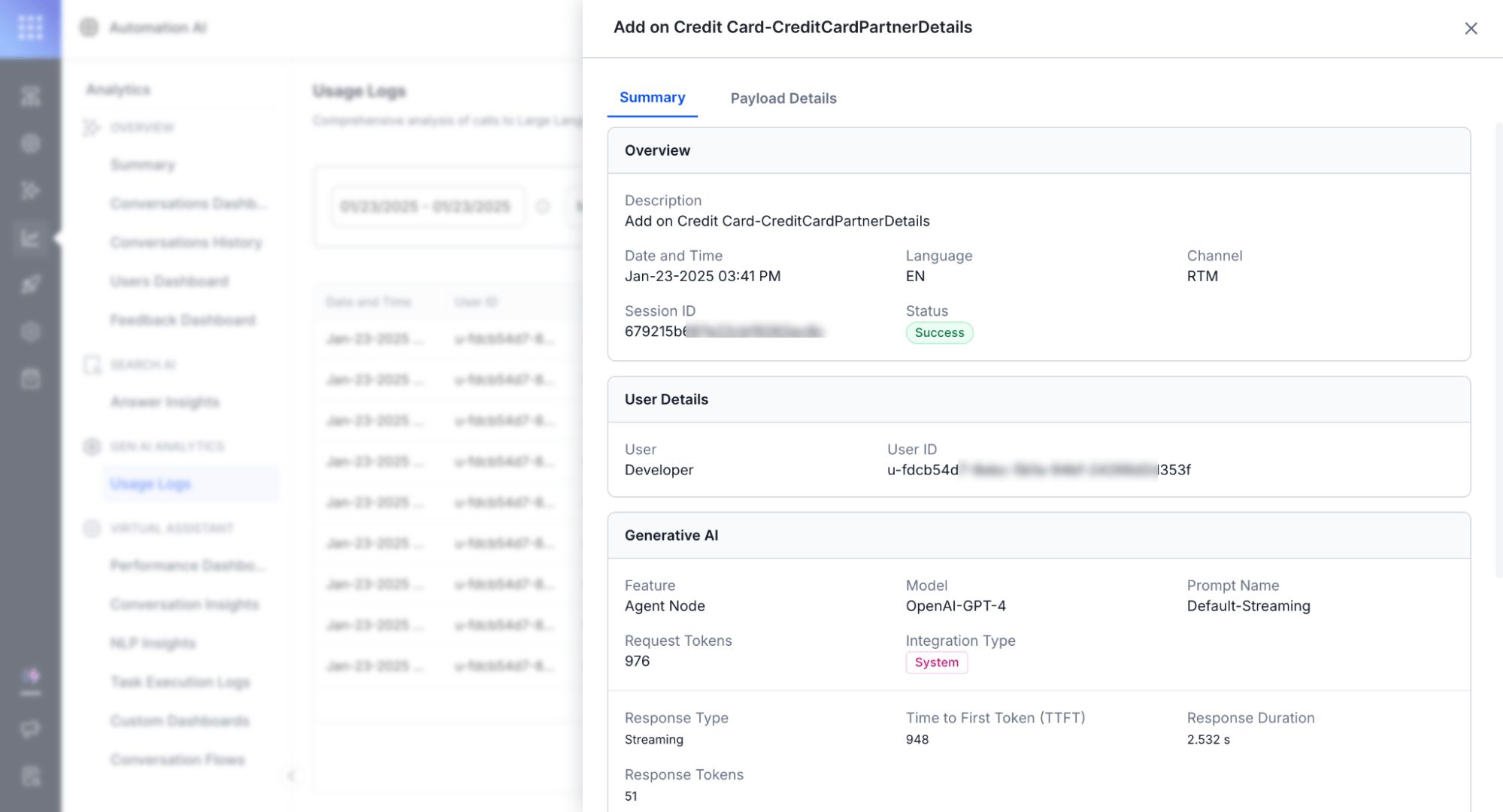
Usage Logs track and differentiate streaming and non-streaming responses.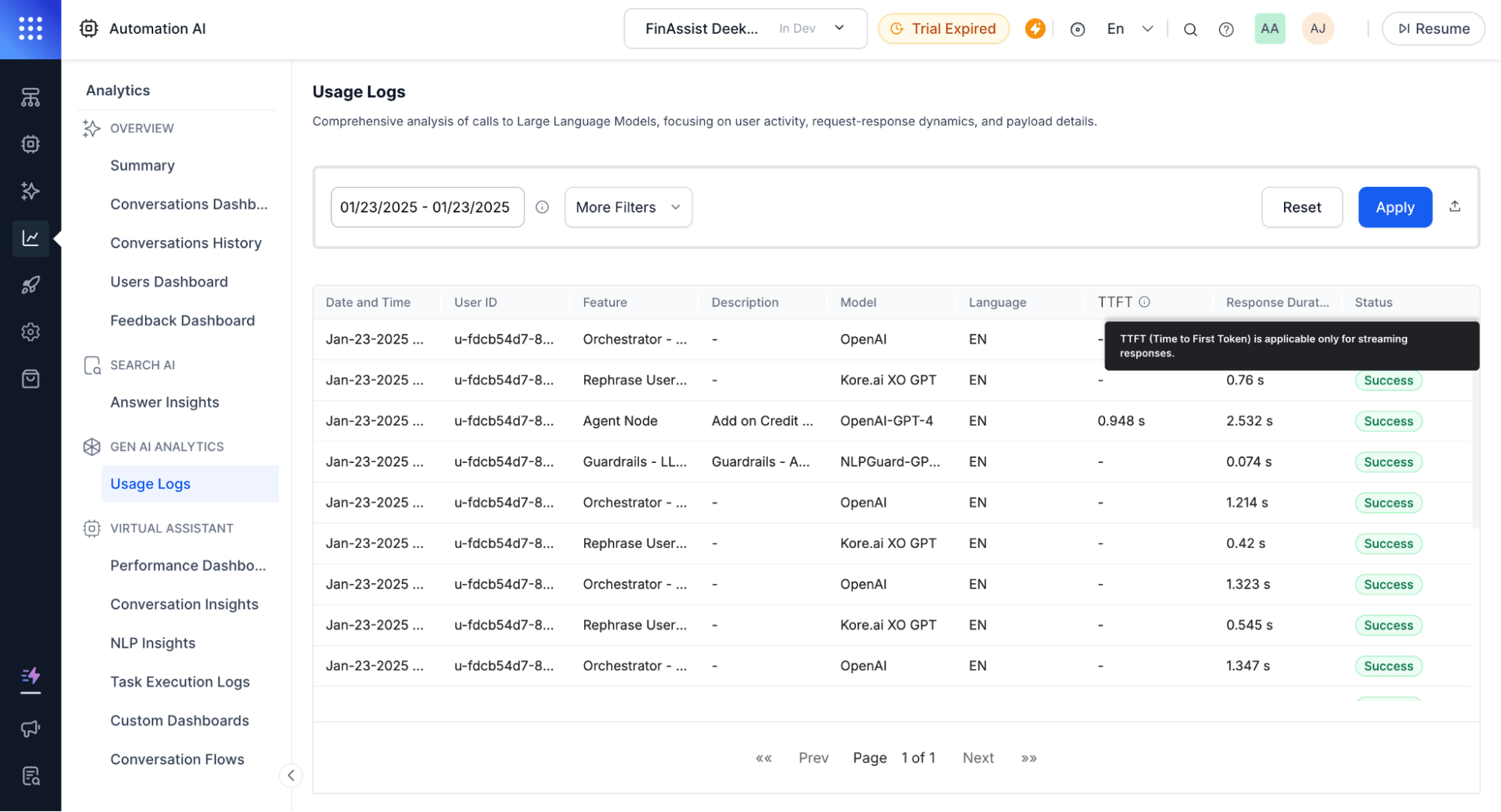
Limitations
Streaming quality depends heavily on prompt design. LLMs are subject to hallucination—ensure prompts are accurate and aligned with desired output before using in production.