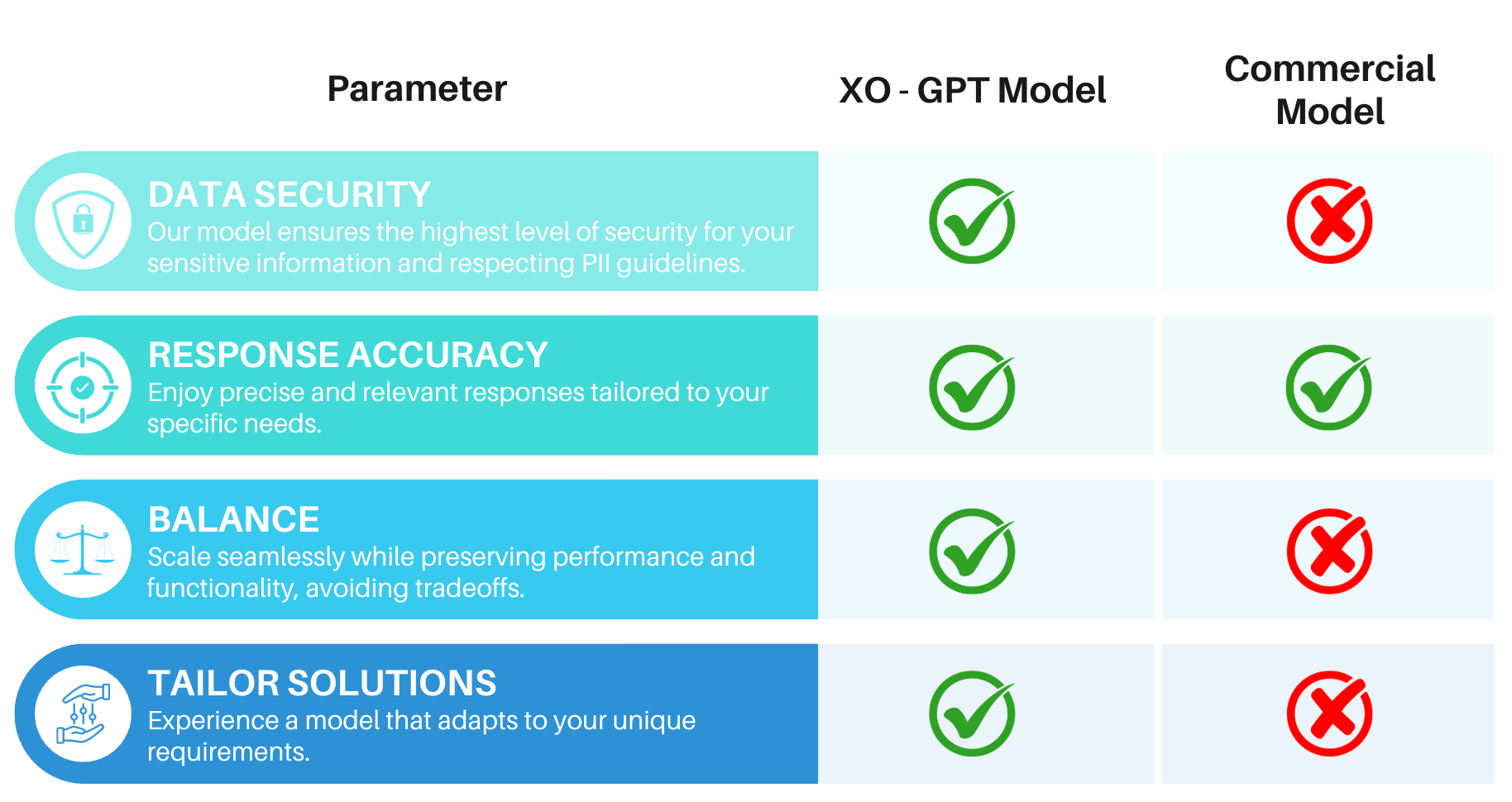
Challenges with Commercial Models
How It Works
The XO GPT Answer Generation model activates immediately after the retrieval phase in the RAG pipeline. It takes retrieved data chunks and generates accurate, contextually relevant answers.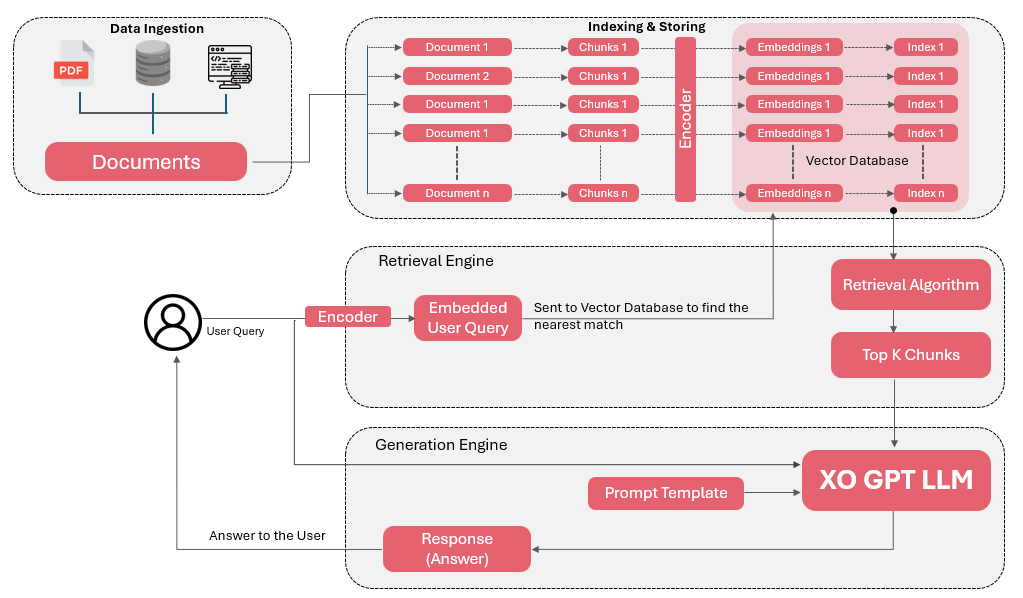
- Answers are generated from text-based data chunks only (not images or video).
- Input queries have been rephrased by the XO GPT User Query Rephrasing Model.
- Retrieved data chunks are assumed to be accurate and relevant.
- Responses are based solely on text; content within links or embedded images isn’t included.
Benefits
Consistent and Accurate
RAG-based retrieval delivers contextually relevant and precise answers. See Model Benchmarks for latency and accuracy metrics.Cost-Effective
For Enterprise Tier customers, XO GPT eliminates commercial model usage costs. Example comparison (10 input tokens/question, 10,000 daily Q&A pairs, 80 tokens/answer):Enhanced Security
No client or user data is used for model retraining. Guardrails: Content moderation, behavioral guidelines, response oversight, input validation, and usage controls. AI Safety: Ethical guidelines, bias monitoring, transparency, and continuous improvement. Performance, features, and language support may vary by implementation. Test thoroughly in your environment before production use.
Use Cases
Sample Output
Ingested chunks:- chk-1: A home loan is a secured loan obtained to purchase property by offering it as collateral. Calculation involves loan amount, interest rate, tenure, and borrower profile.
- chk-4: EMI = [P × R × (1+R)^N] / [(1+R)^N−1], where P = principal, R = monthly interest rate, N = number of installments.
The EMI is calculated using the formula: EMI = [P × R × (1+R)^N] / [(1+R)^N−1], where P is the principal loan amount, R is the monthly interest rate, and N is the number of monthly installments [chk-4].Q: What’s a home loan? What’s photosynthesis?
I found only the answer to one question ‘what’s a home loan?’: A home loan is a secured loan obtained to purchase property by offering it as collateral [chk-1]. The remaining questions can’t be answered from the given context.
Model Building Process
See Model Building Process.Model Benchmarks
Version 3.0
Model Choice
Base model: Llama 3.1 8B InstructPrompt Tuning
Prompts are designed to produce clear, well-structured outputs with a consistent tone. Each prompt variation is evaluated across multiple categories (toxicity, bias, ambiguity, hallucination, logical consistency, robustness) in English and multiple translated languages. The prompt with the highest accuracy and reliability across all scenarios is selected.AWQ Model Quantization
AWQ (Activation-aware Weight Quantization) reduces memory and compute requirements while maintaining accuracy.Model Usage Notes
- Context-only responses: The model responds based solely on the source document. It doesn’t use external knowledge.
- Language consistency: Query and source document must be in the same language.
- Output formatting: Supports formatting cues in the query (for example, “provide the answer in bullet points”, “explain step-by-step”).
Benchmarks Summary v3
Comparison models: Llama 3.1 8B, Claude 3.5 Sonnet, Mistral 7B v2.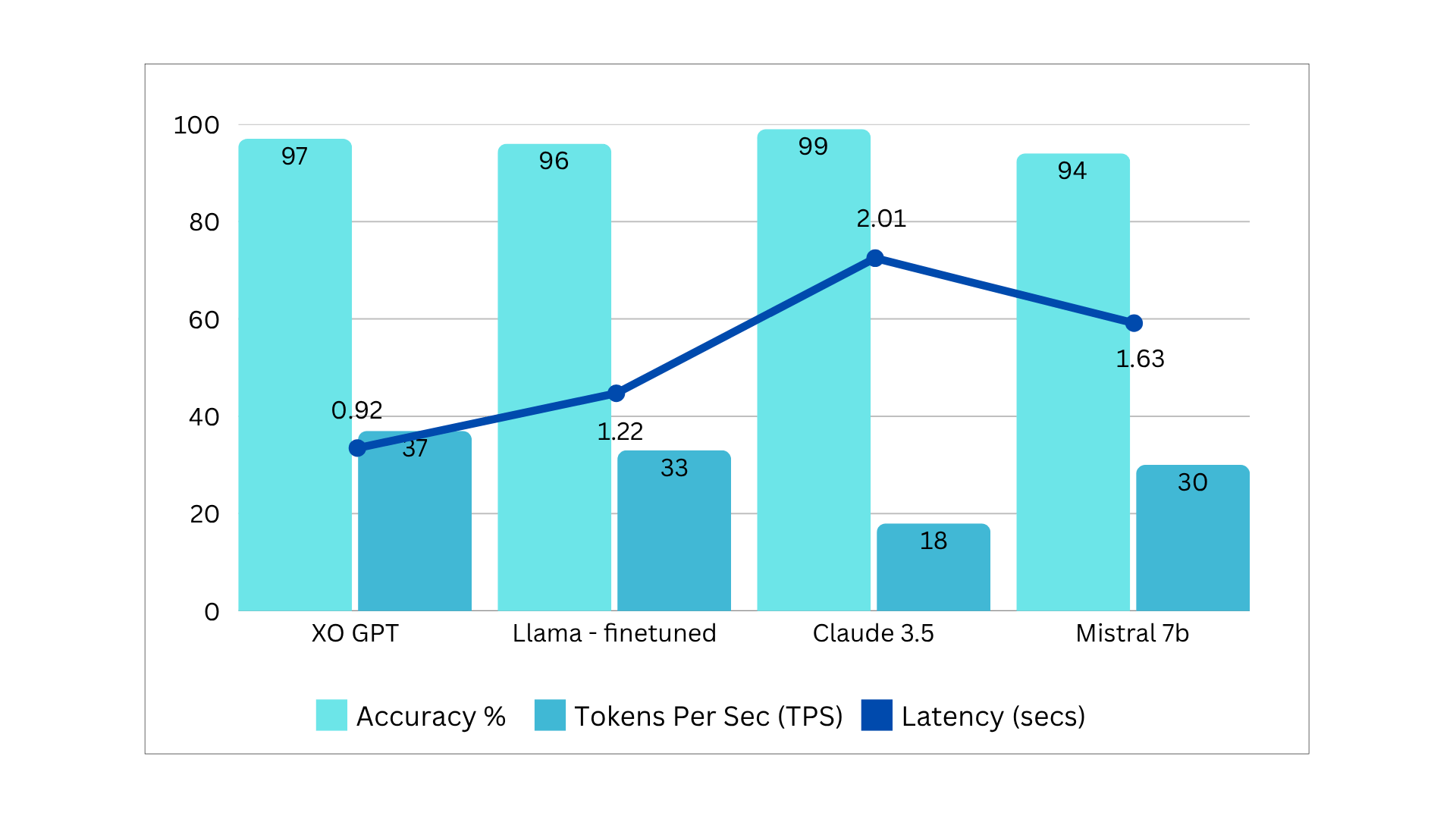
Version 2.0
Model Choice
Base model: Llama 3.1 8B InstructFine-Tuning Parameters
General Parameters
Infrastructure: 2× A10 GPUs. Requires an Agent AI License.AWQ Model Quantization
Same configuration as v3.0. See AWQ parameters above.Benchmarks Summary v2
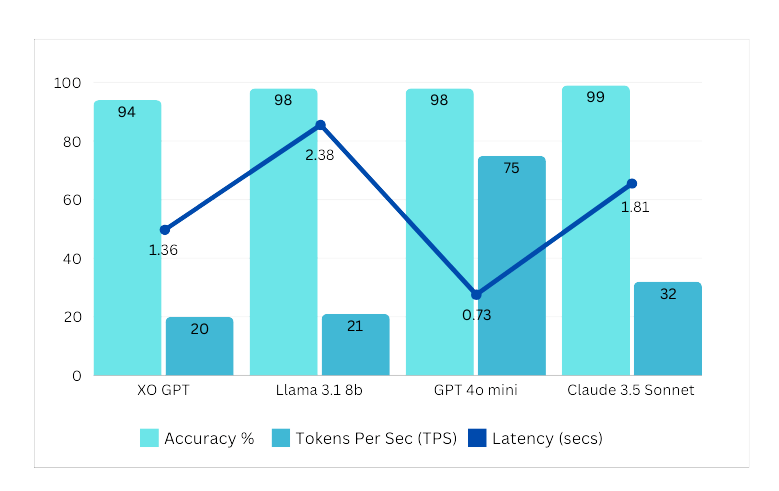
Comparison models: Mistral 7B v2, Llama 3.1 8B, GPT-4o Mini, Claude 3.5 Sonnet.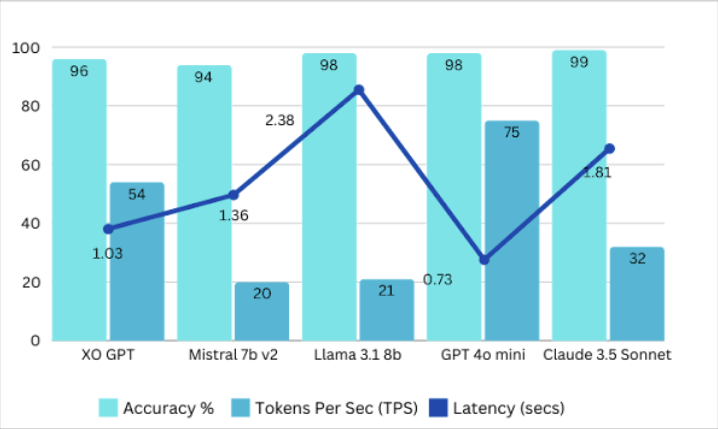
Version 1.0
Model Choice
Base model: Mistral 7B Instruct v0.2Fine-Tuning Parameters
General Parameters
Infrastructure: 2× A10 GPUs. Requires an Agent AI License.Benchmarks Summary v1
Comparison models: Llama 3.1 8B, GPT-4o Mini, Claude 3.5 Sonnet.