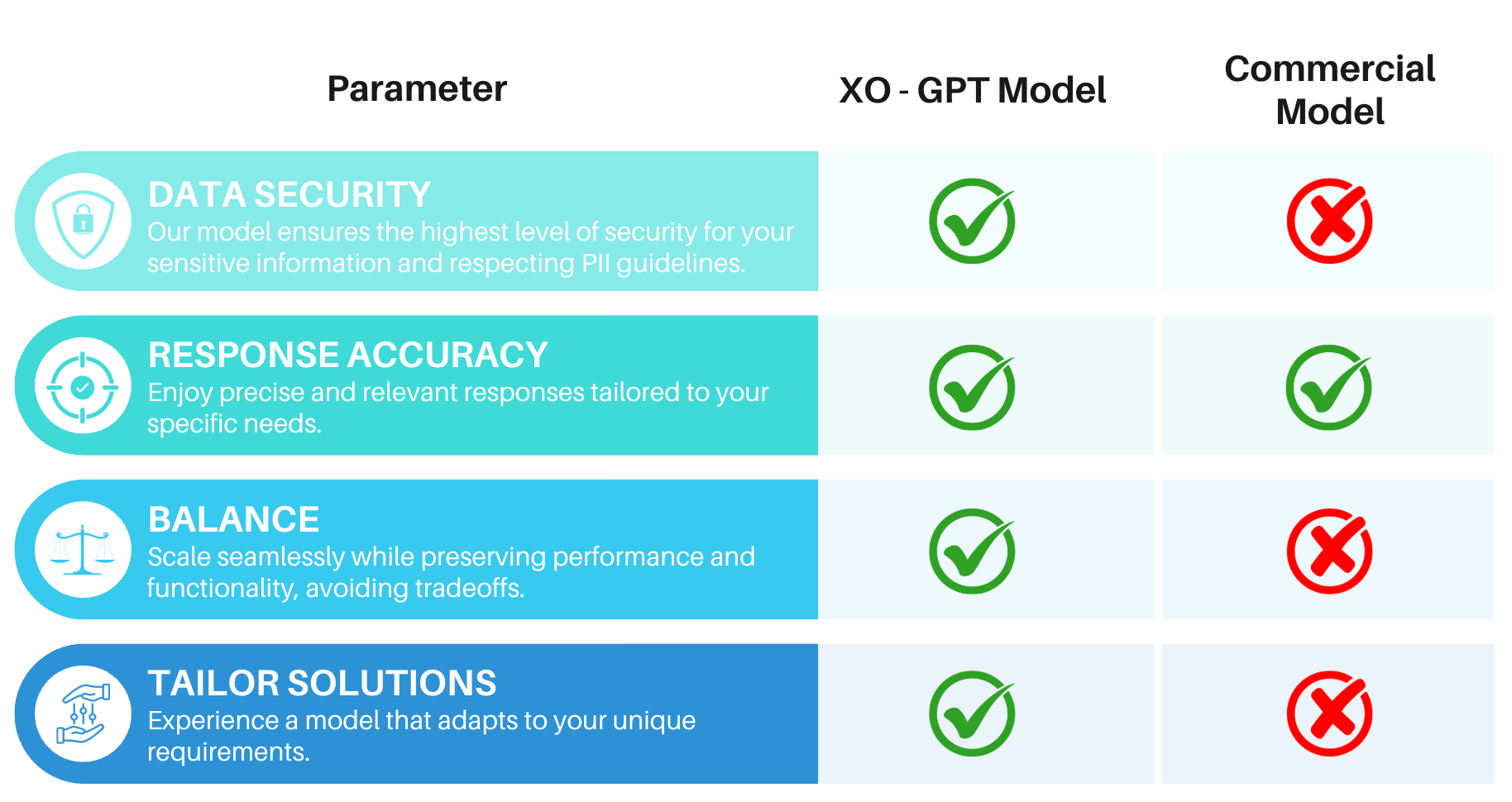
Challenges with Commercial Models
Key Assumptions
- Designed for text-based conversations only.
- Assumes structured conversational data with clear speaker delineation.
Benefits
Consistent and Accurate
Delivers precise, contextually relevant summaries for conversation transcripts. See Model Benchmarks for latency and accuracy metrics.Cost-Effective
For Enterprise Tier customers, XO GPT eliminates commercial model usage costs. Example comparison (250 input tokens/conversation, 1,000 daily summaries, 120 tokens/summary):Enhanced Security
No client or user data is used for model retraining. Guardrails: Content moderation, behavioral guidelines, response oversight, input validation, and usage controls. AI Safety: Ethical guidelines, bias monitoring, transparency, and continuous improvement. Performance, features, and language support may vary by implementation. Test thoroughly in your environment before production use.
Use Cases
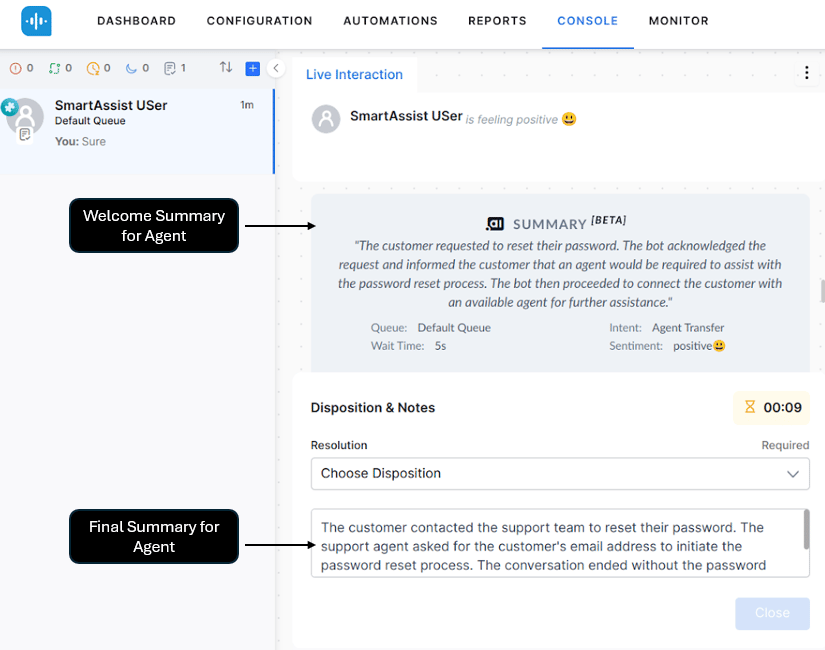
Sample Output
Conversation:The customer contacted support to check the status of their order. The AI Agent verified the customer’s identity and informed them their order would ship within 48 hours. The customer then requested to speak with an agent to verify their shipping address. The agent confirmed the address on file was correct. The conversation ended with the customer satisfied.
Model Building Process
See Model Building Process.Model Benchmarks
Version 2.0
Model Choice
Base model: Mistral 7B Instruct v0.2Fine-Tuning Parameters
General Parameters
Infrastructure: 2× A10 GPUs. Requires an Agent AI License.AWQ Model Quantization
Benchmarks Summary v2
Comparison models: LLama-8B, GPT-4, Claude 3 Sonnet.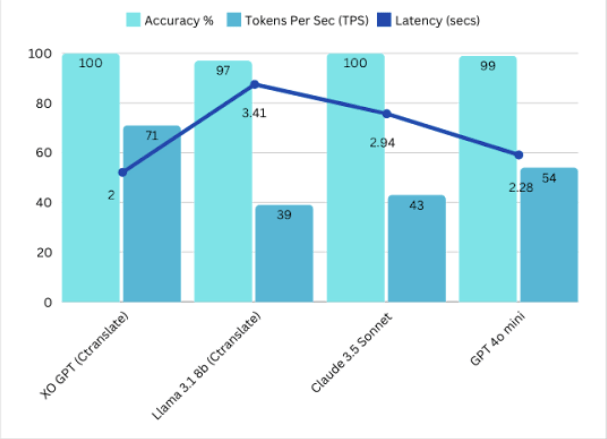
Version 1.0
Model Choice
Base model: Mistral 7B Instruct v0.2Fine-Tuning Parameters
General Parameters
Infrastructure: 2× A10 GPUs. Requires an Agent AI License.Benchmarks Summary v1
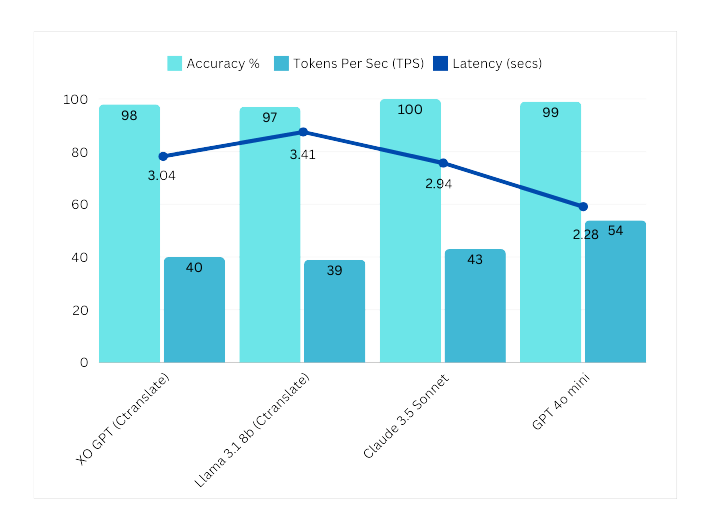
Comparison models: Llama 3 8B (Ctranslate), Sonnet 3.5, GPT-4o.