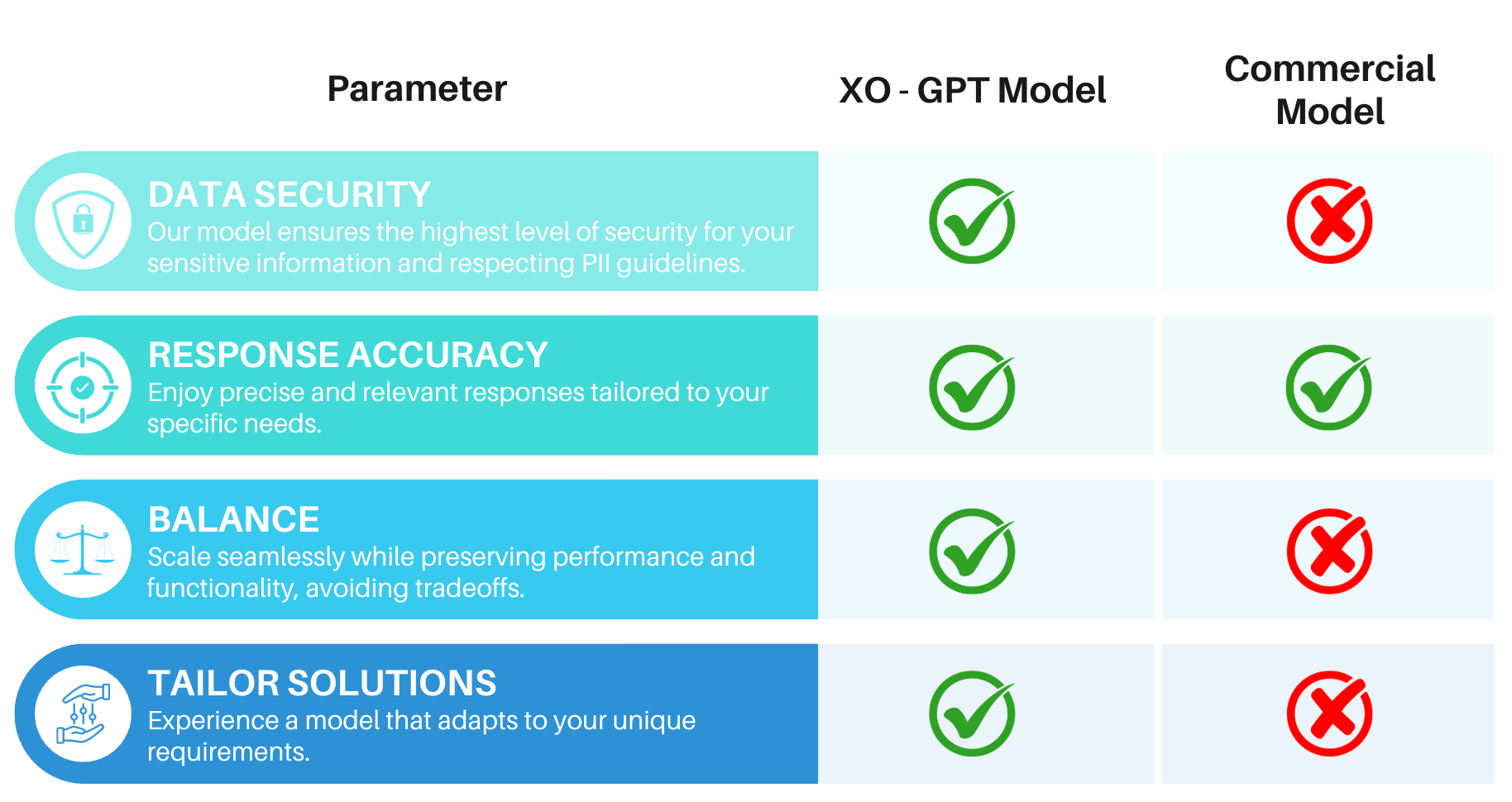
Challenges with Commercial Models
Key Assumptions
- Designed for text-based conversations only.
- Rephrases AI Agent responses only; doesn’t modify user inputs.
Benefits
Empathetic and Contextual Communication
Tailors responses to user sentiment and tone for engaging, empathetic interactions. See Model Benchmarks for performance metrics.Cost-Effective
For Enterprise Tier customers, XO GPT eliminates commercial model usage costs. Example comparison (120 input tokens/conversation, 10,000 daily interactions, 40 tokens/response):Enhanced Security
No client or user data is used for model retraining. Guardrails: Content moderation, behavioral guidelines, response oversight, input validation, and usage controls. AI Safety: Ethical guidelines, bias monitoring, transparency, and continuous improvement.Performance, features, and language support may vary by implementation. Test thoroughly in your environment before production use.
Use Cases
Sample Output
Conversation:Absolutely, your worries are entirely understandable. However, please be assured that airlines are practicing stringent safety measures to ensure the well-being of all passengers. Now, could you please share your preferred flight time?
Model Building Process
See Model Building Process.Model Benchmarks
Version 1.0
Model Choice
Base model: Mistral 7B Instruct v0.2Fine-Tuning Parameters
General Parameters
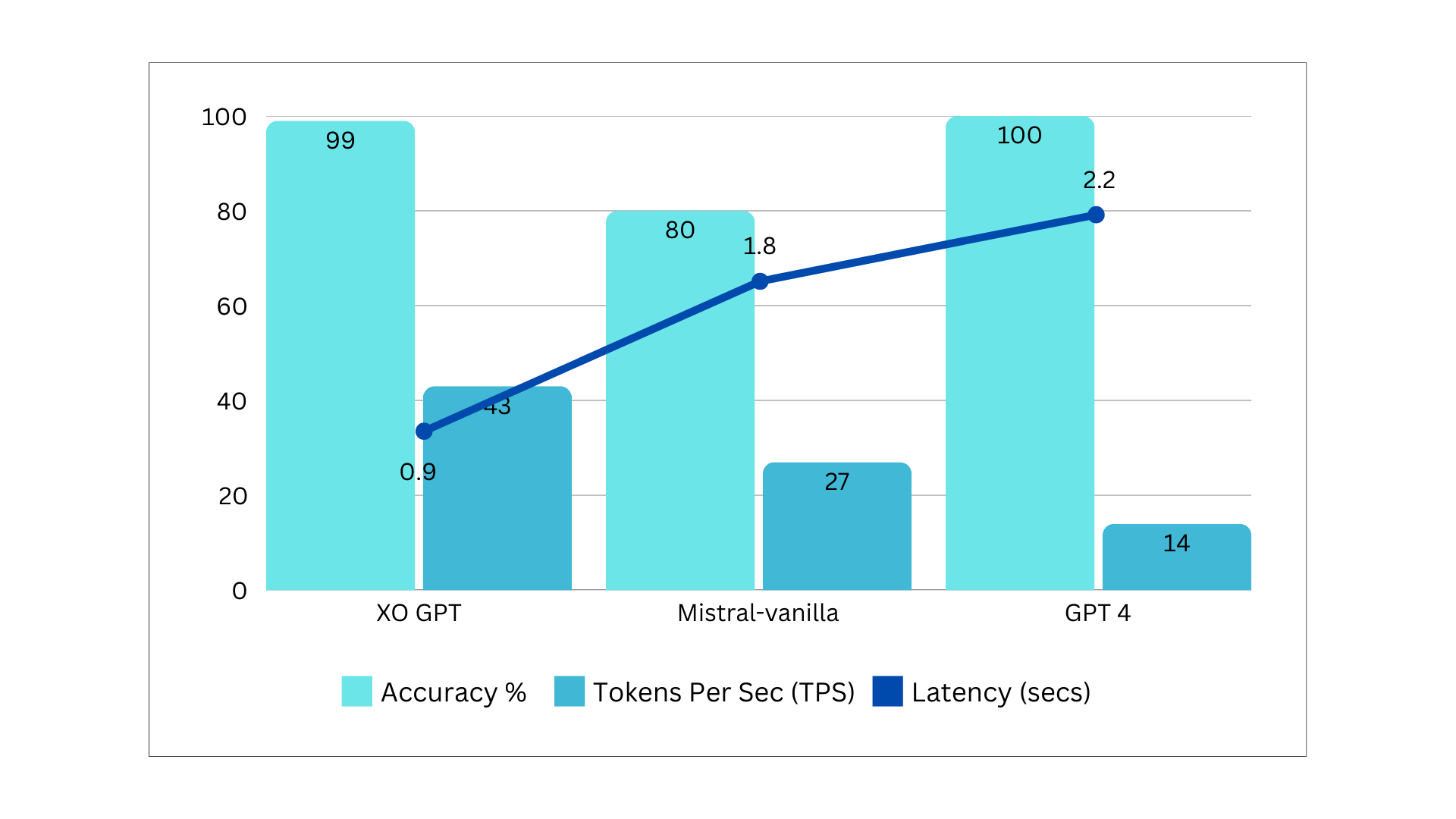
Infrastructure: A10 (g5-xlarge).Benchmarks Summary v1
Comparison models: Mistral-vanilla, GPT-4.