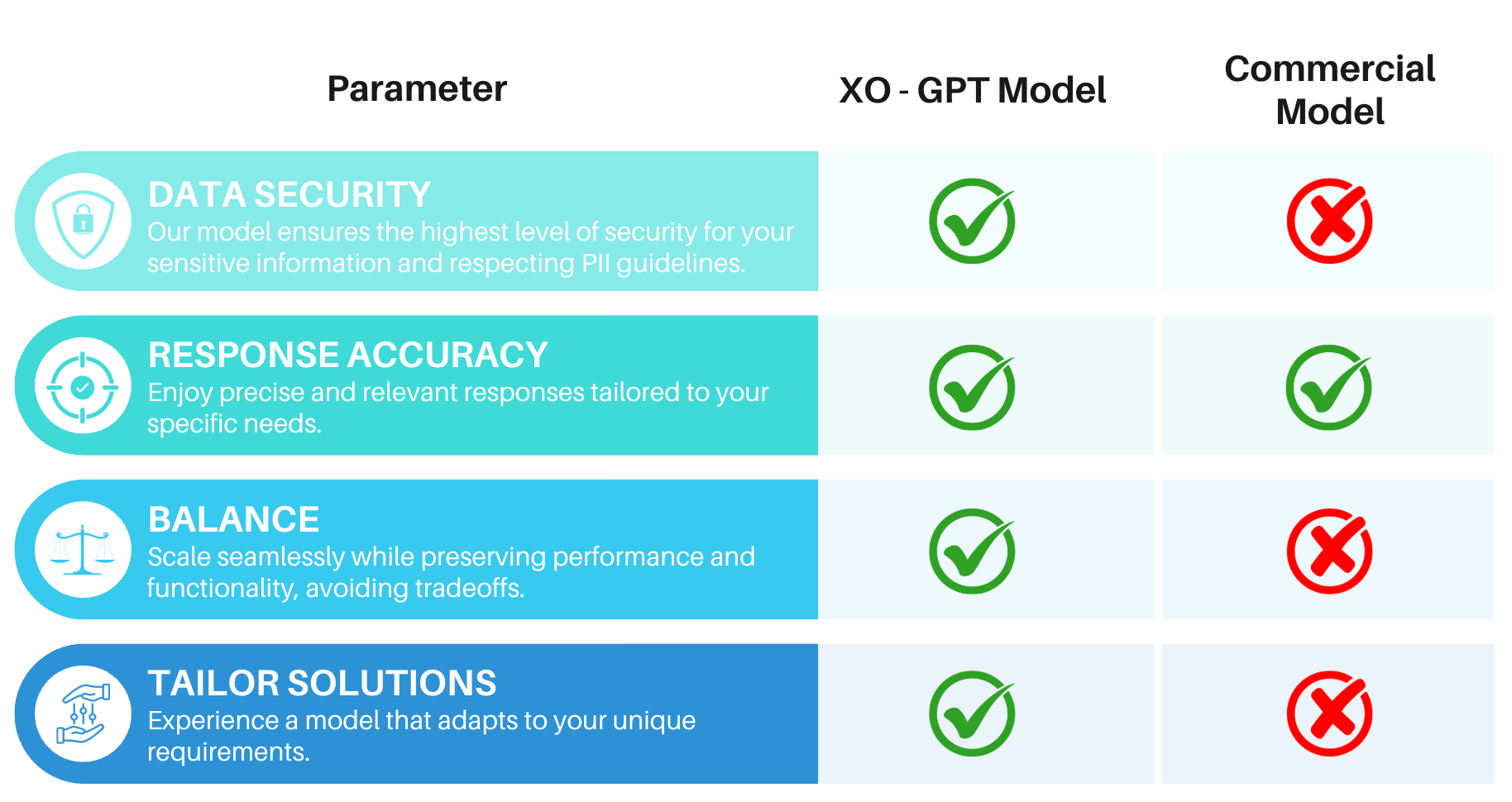
Challenges with Commercial Models
Key Assumptions
- Designed for text-based conversations only.
- Paraphrases the user query only when it references or co-refers to details from prior conversation context. Other queries are passed through unchanged.
Benefits
Contextual Communication
Adapts user queries to the conversation context, enabling accurate intent interpretation for meaningful interactions. See Model Benchmarks for performance insights.Cost-Effective
For Enterprise Tier customers, XO GPT eliminates commercial model usage costs. Example comparison (100 input tokens/conversation, 10,000 daily interactions, 15 tokens/response):Enhanced Security
No client or user data is used for model retraining. Guardrails: Content moderation, behavioral guidelines, response oversight, input validation, and usage controls. AI Safety: Ethical guidelines, bias monitoring, transparency, and continuous improvement.Performance, features, and language support may vary by implementation. Test thoroughly in your environment before production use.
Use Cases
Sample Output
Conversation:User: Ok, I will choose to apply at Stanford University for a Physics course.
Model Building Process
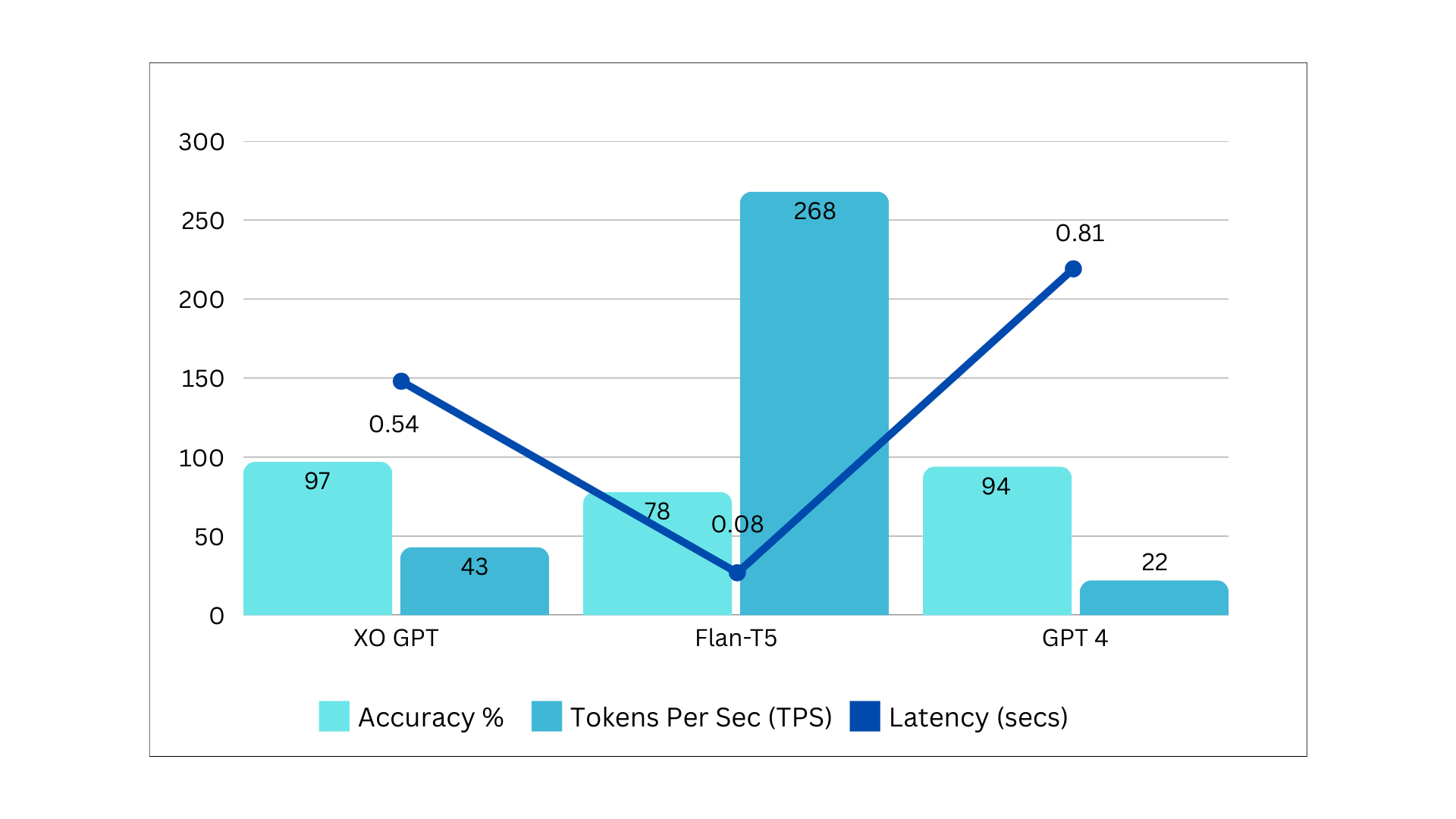
See Model Building Process.Model Benchmarks
Version 1.0
Model Choice
Base model: Mistral 7B Instruct v0.2Fine-Tuning Parameters
General Parameters
Infrastructure: A10 (g5-xlarge).Benchmarks Summary v1
Comparison models: Flan-T5, GPT-4.